Statistical Power
The Central Limit Theorem (part I)
The sampling distribution approximates the shape of a normal distribution


The Central Limit Theorem (part II)
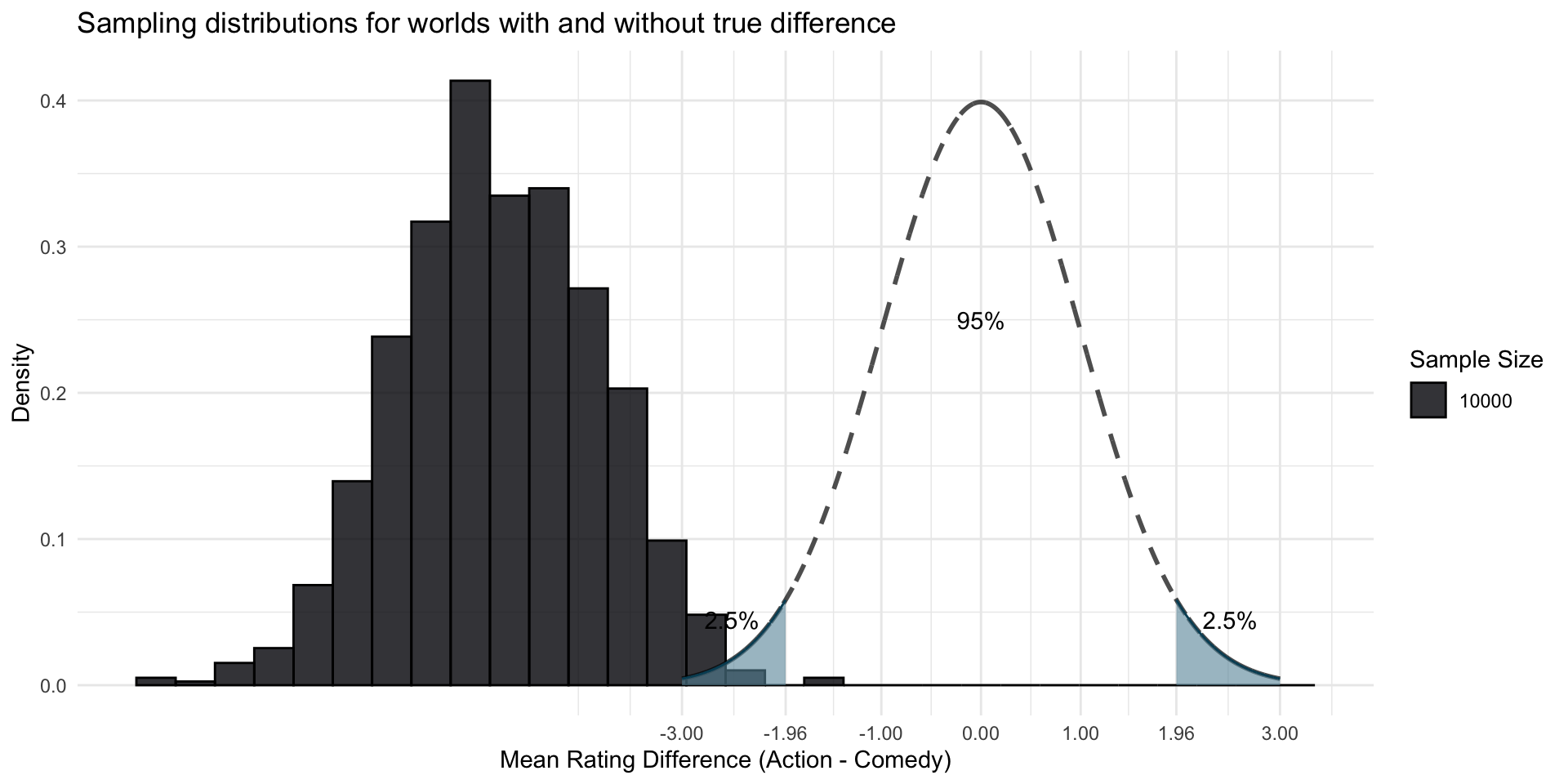
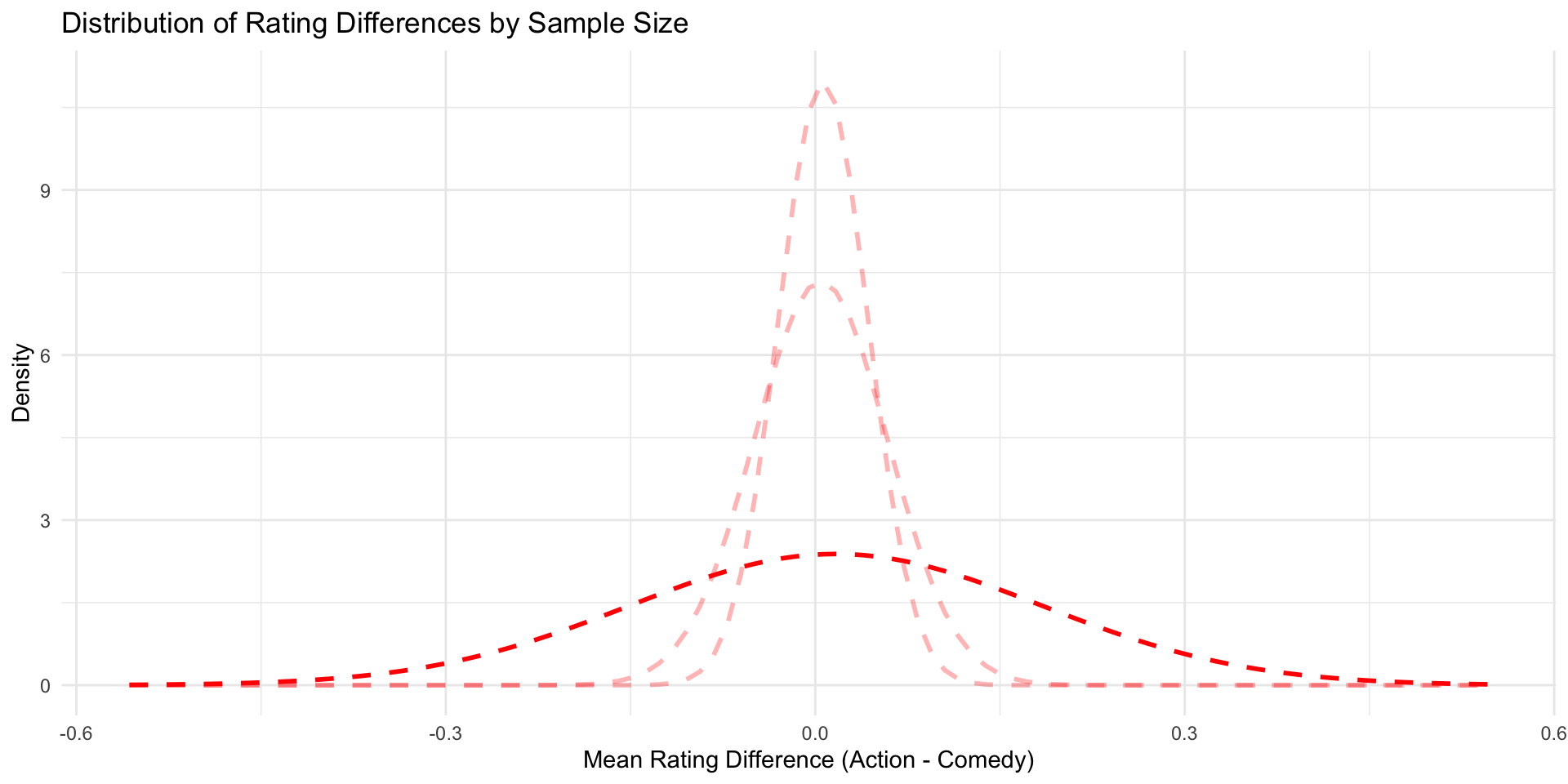
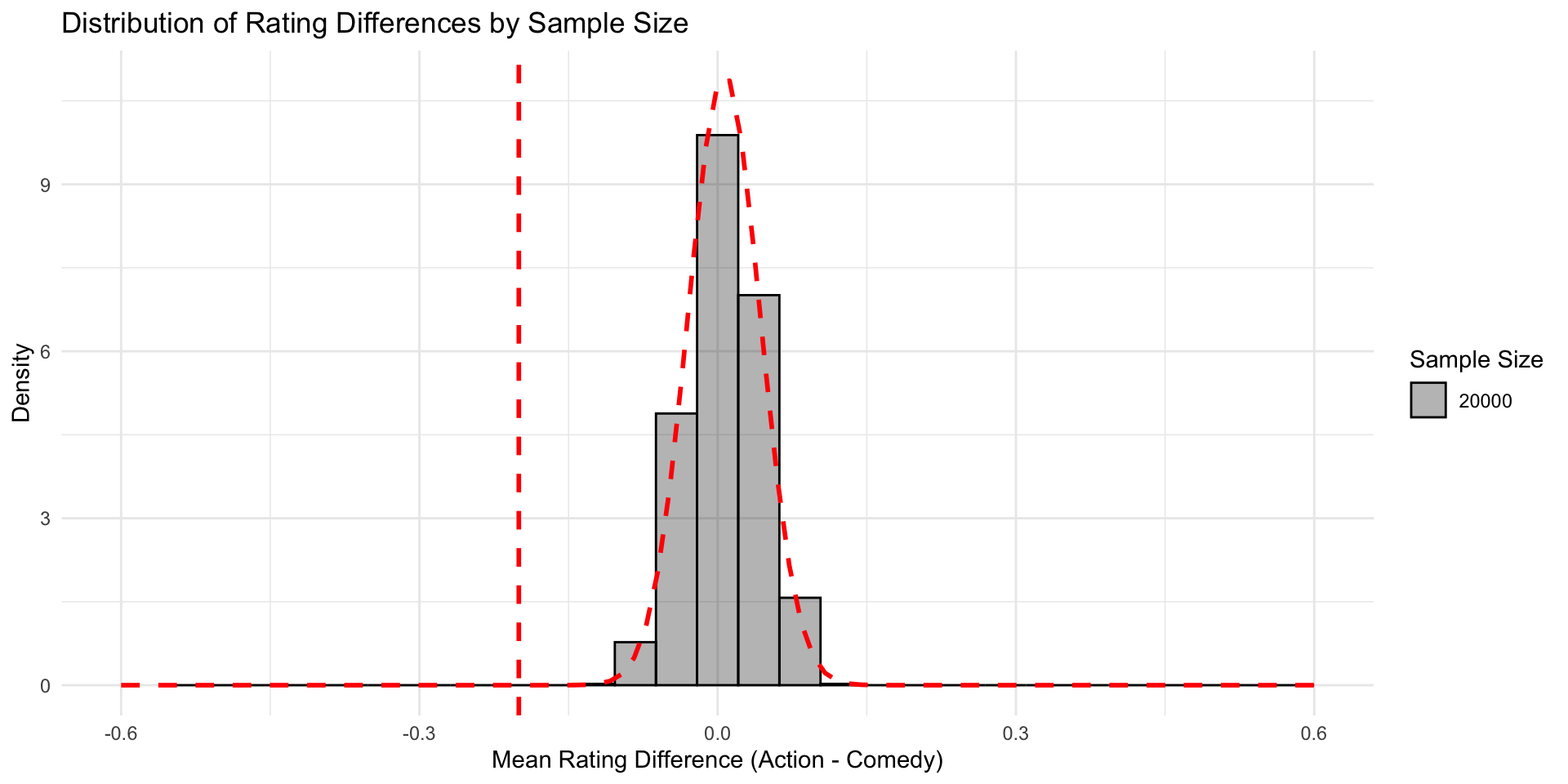
This is what the sampling distribution looks like with samples of size 10,000

The Central Limit Theorem (part II)
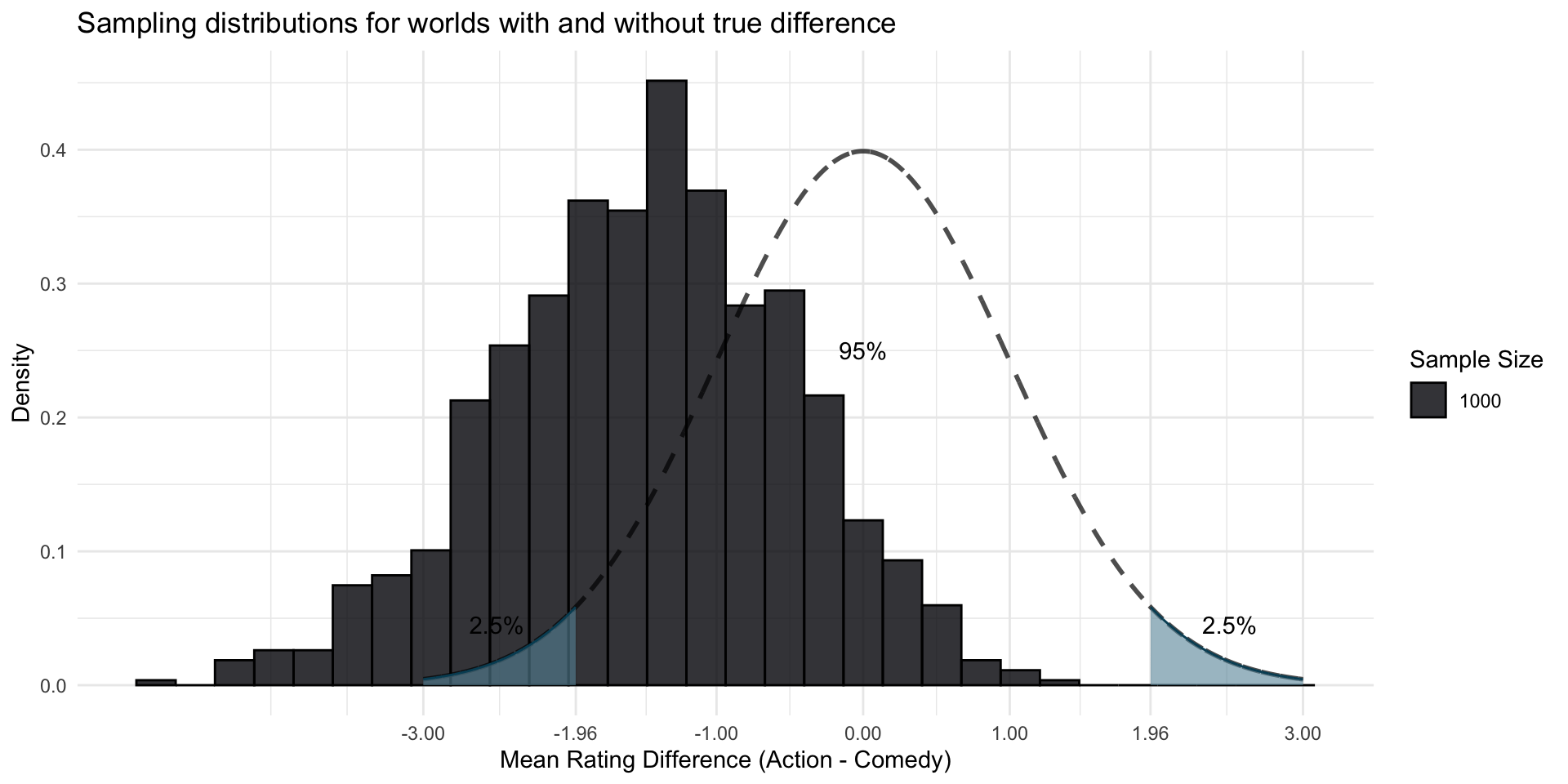
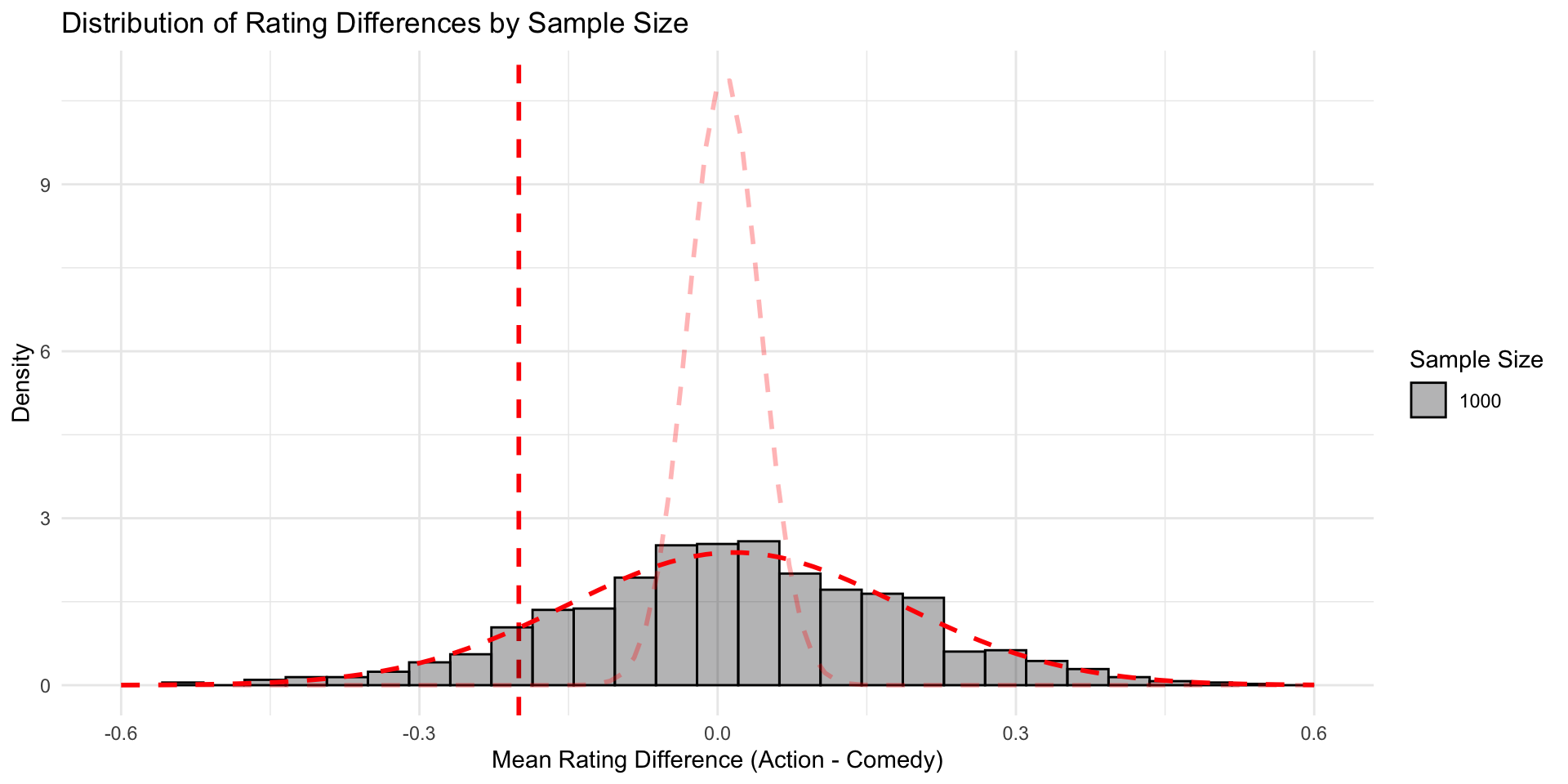
And with samples of size 1,000
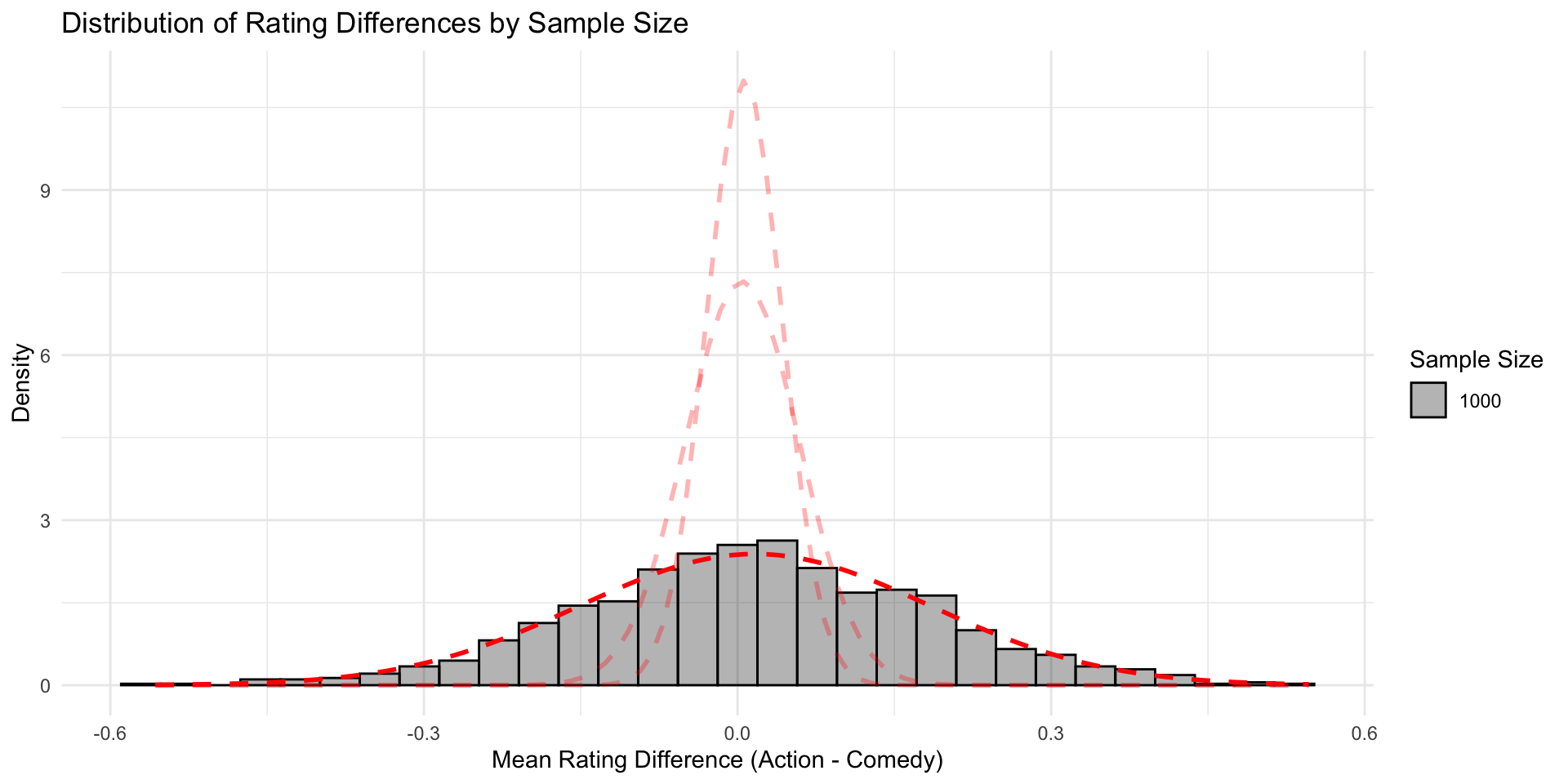
The Central Limit Theorem (part II)
The smaller the sample, the larger the standard deviation of the sampling distribution
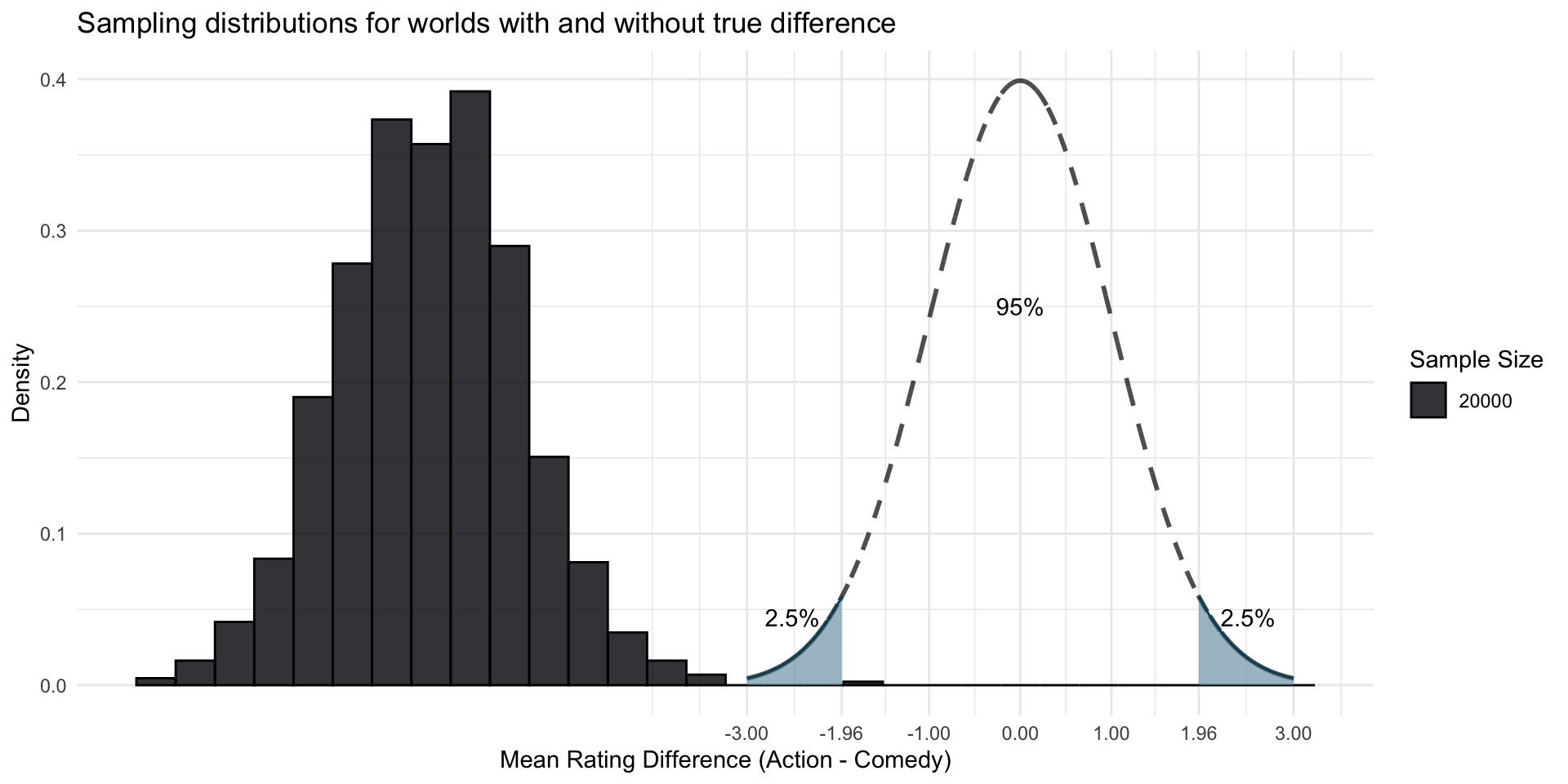
In a sample based on 20’000 movies, that seems reasonably unlikely in a Null world
But the same effect in a sample of 1000 seems not so unlikely…
Let’s plot the population data
Code
# Compute means
means <- imaginary_movies_true |>
group_by(genre) |>
summarize(mean_rating = mean(rating)) |>
# Adjust vertical placement for text labels
mutate(label_y = c(0.08, 0.06))
# Plot
ggplot(imaginary_movies_true, aes(x = rating, fill = genre)) +
geom_histogram(aes(y = ..density..), bins = 30, alpha = 0.5, position = "identity") +
scale_fill_viridis_d(option = "plasma", begin = 0.2, end = 0.8) + # Viridis color scale
scale_color_viridis_d(option = "plasma", begin = 0.2, end = 0.8) + # Viridis color scale
geom_vline(data = means, aes(xintercept = mean_rating, color = genre),
linetype = "dashed", size = 1, show.legend = FALSE) + # Remove color legend for lines
geom_text(data = means, aes(x = mean_rating, y = label_y, label = round(mean_rating, 2)),
hjust = -0.1, fontface = "bold") + # Adjusted position to avoid overlap
labs(title = "Distribution of Movie Ratings by Genre",
x = "Rating",
y = "Density",
fill = "Genre") +
theme_minimal() 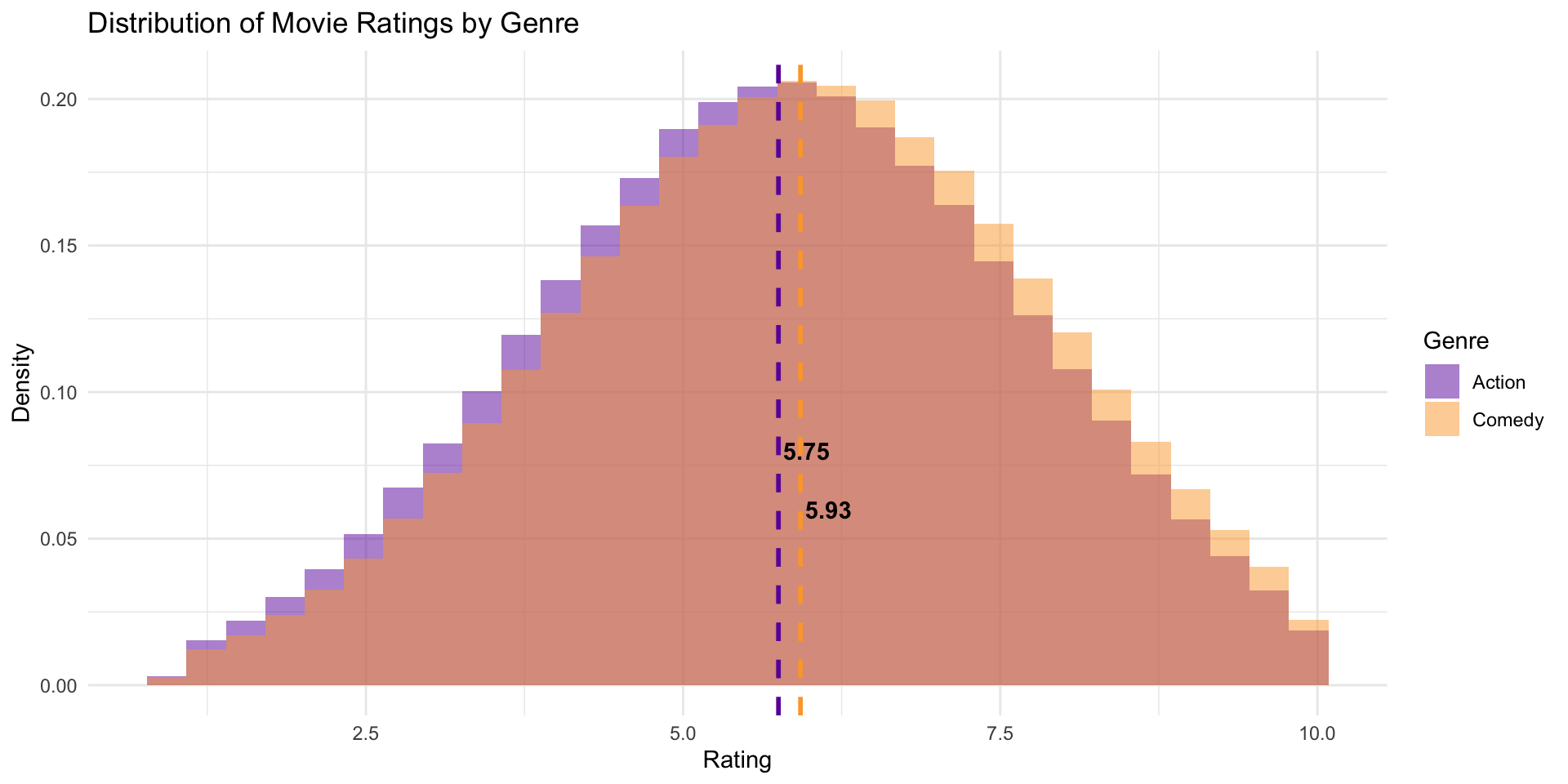
🎉 It worked, we see our imagined effect of ~ -0.2
Code
# Compute means
means <- imaginary_movies_true |>
group_by(genre) |>
summarize(mean_rating = mean(rating)) |>
# Adjust vertical placement for text labels
mutate(label_y = c(0.08, 0.06))
# Plot
ggplot(imaginary_movies_true, aes(x = rating, fill = genre)) +
geom_histogram(aes(y = ..density..), bins = 30, alpha = 0.5, position = "identity") +
scale_fill_viridis_d(option = "plasma", begin = 0.2, end = 0.8) + # Viridis color scale
scale_color_viridis_d(option = "plasma", begin = 0.2, end = 0.8) + # Viridis color scale
geom_vline(data = means, aes(xintercept = mean_rating, color = genre),
linetype = "dashed", size = 1, show.legend = FALSE) + # Remove color legend for lines
geom_text(data = means, aes(x = mean_rating, y = label_y, label = round(mean_rating, 2)),
hjust = -0.1, fontface = "bold") + # Adjusted position to avoid overlap
labs(title = "Distribution of Movie Ratings by Genre",
x = "Rating",
y = "Density",
fill = "Genre") +
theme_minimal() 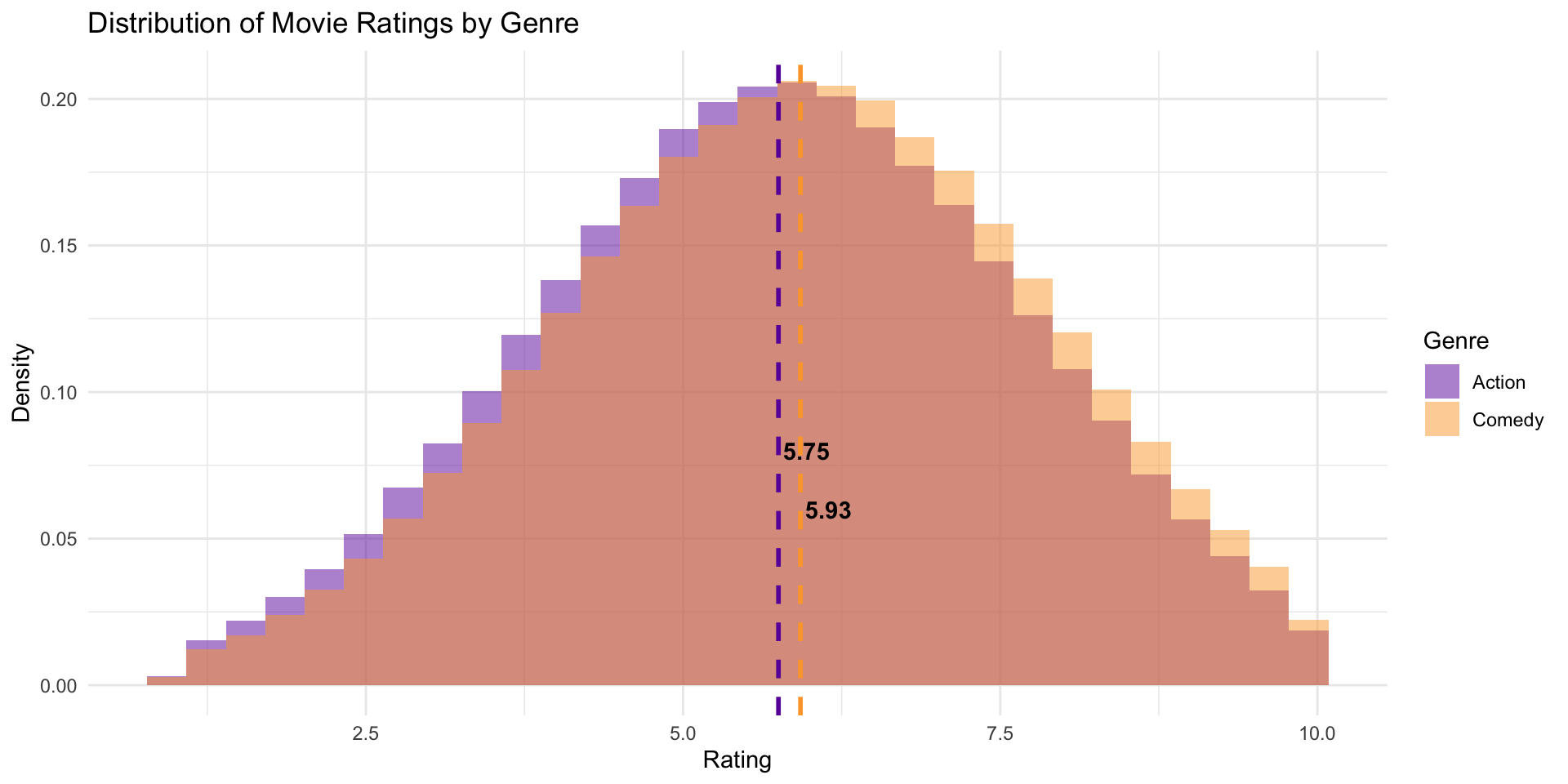
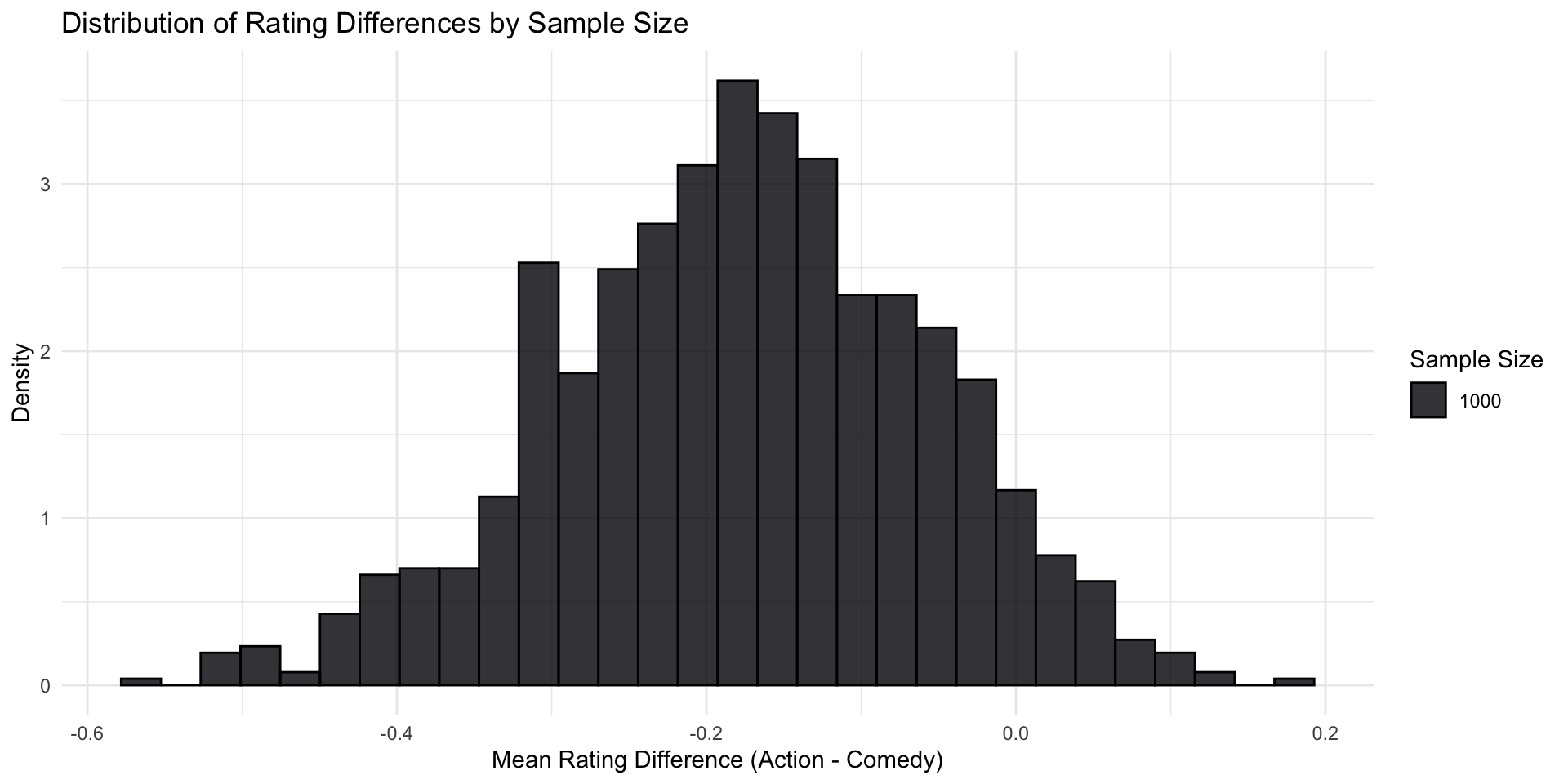
This is what our sampling distribution would look like
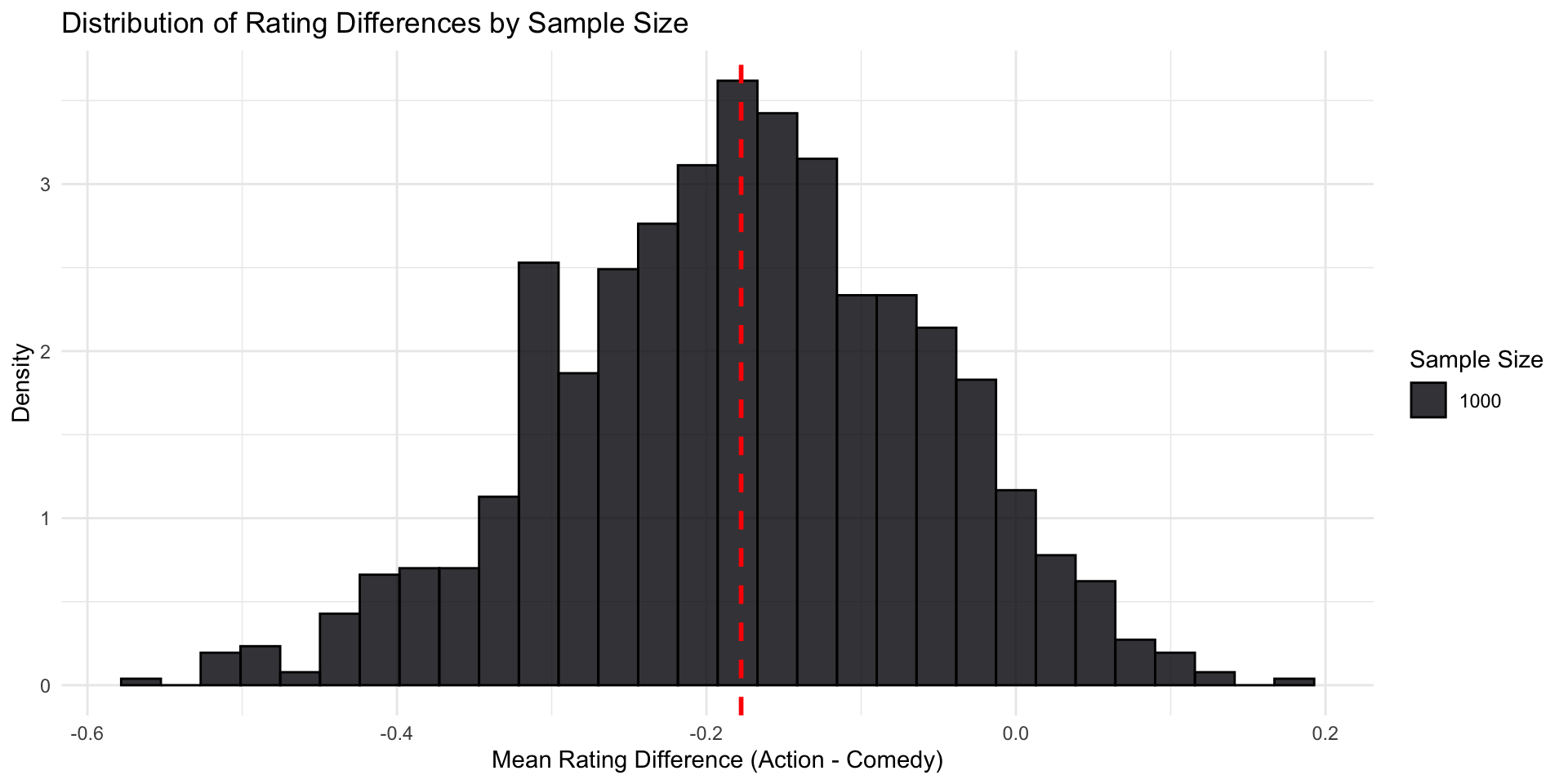

We can plot both simulated worlds together.
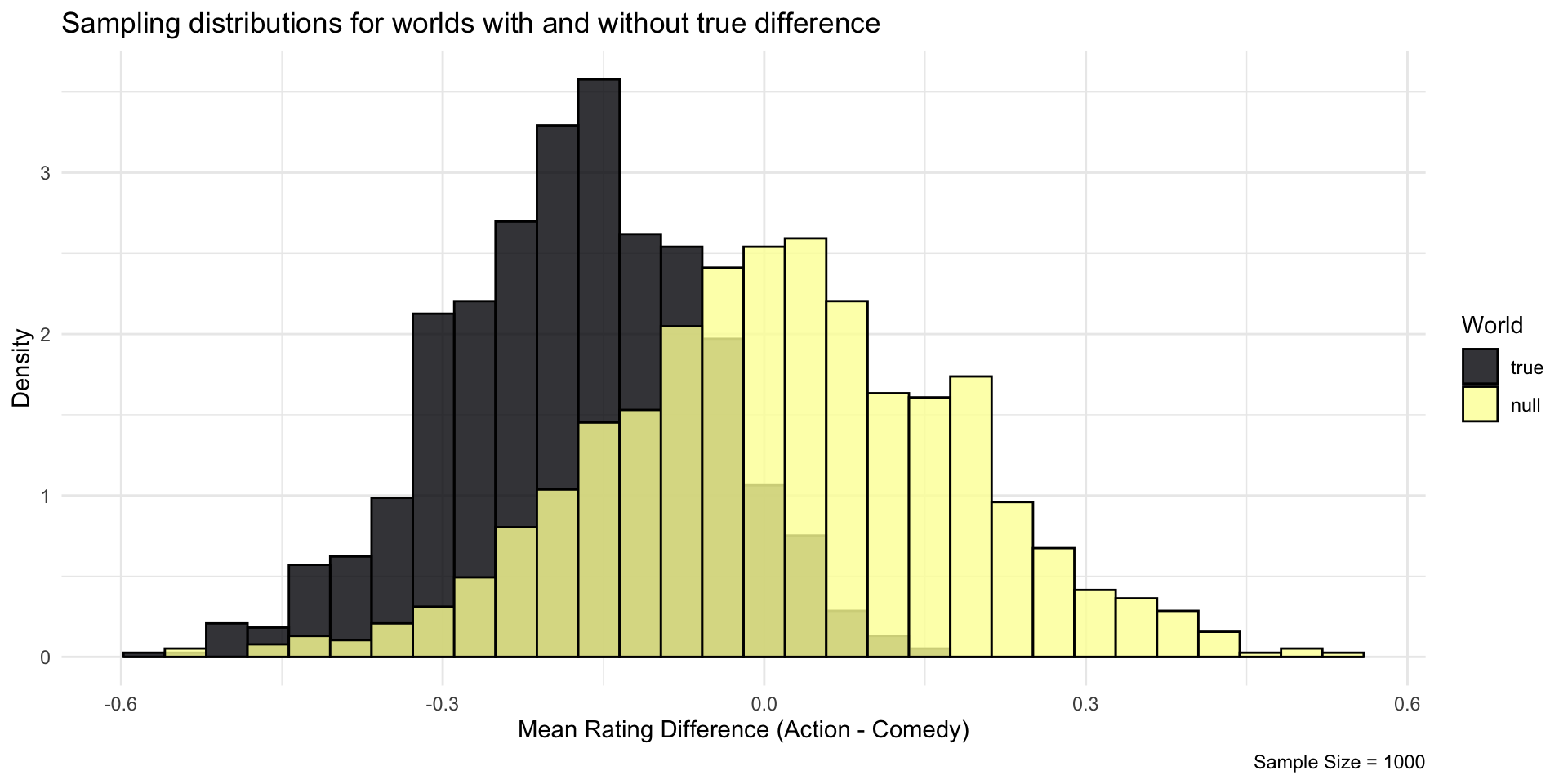
Let’s bring both worlds on the scale of a standard normal distribution, dividing their respective standard deviation
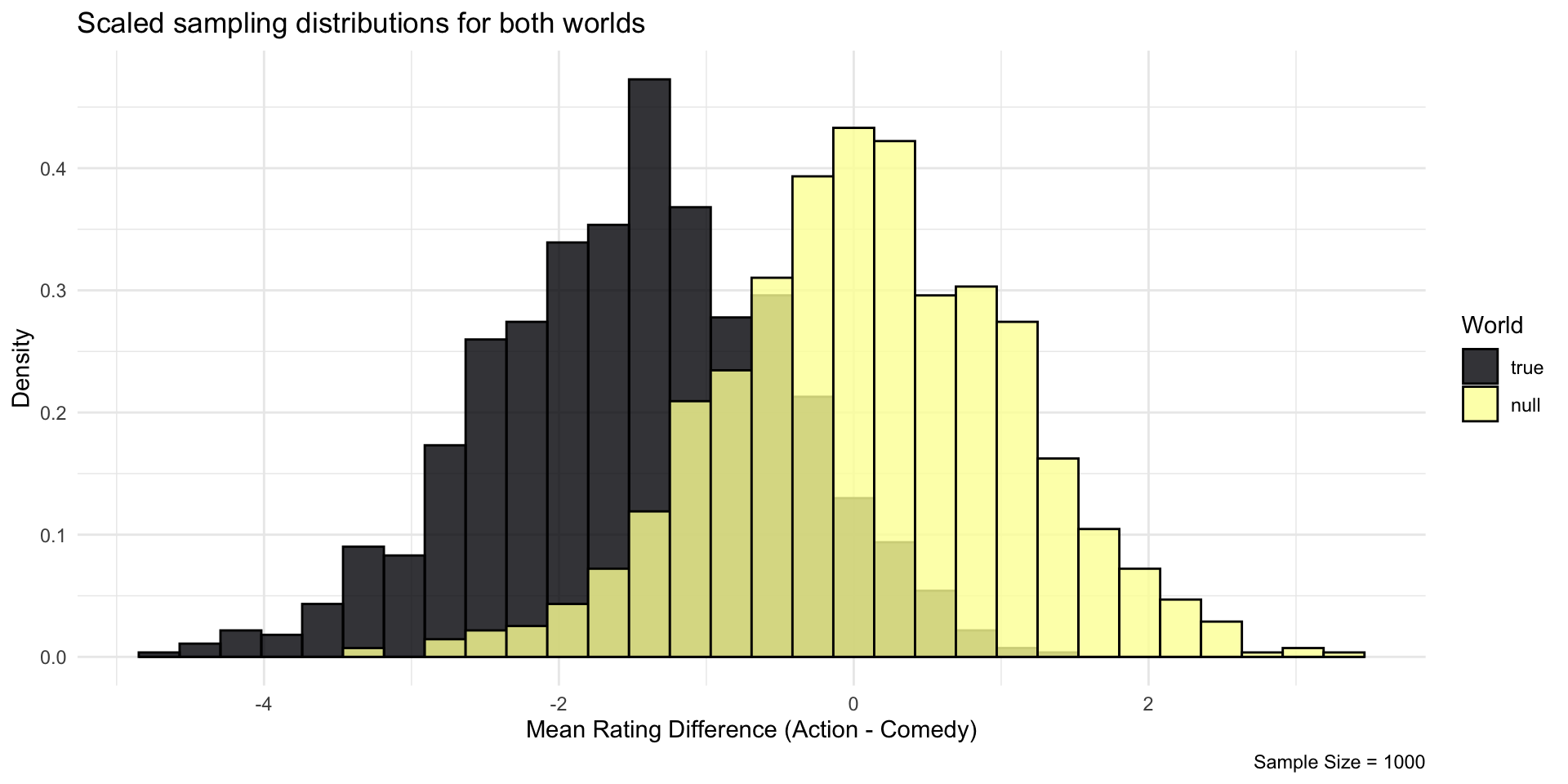

With a sample size of 1000, in many cases, we would say: “This could have occurred in a Null World”
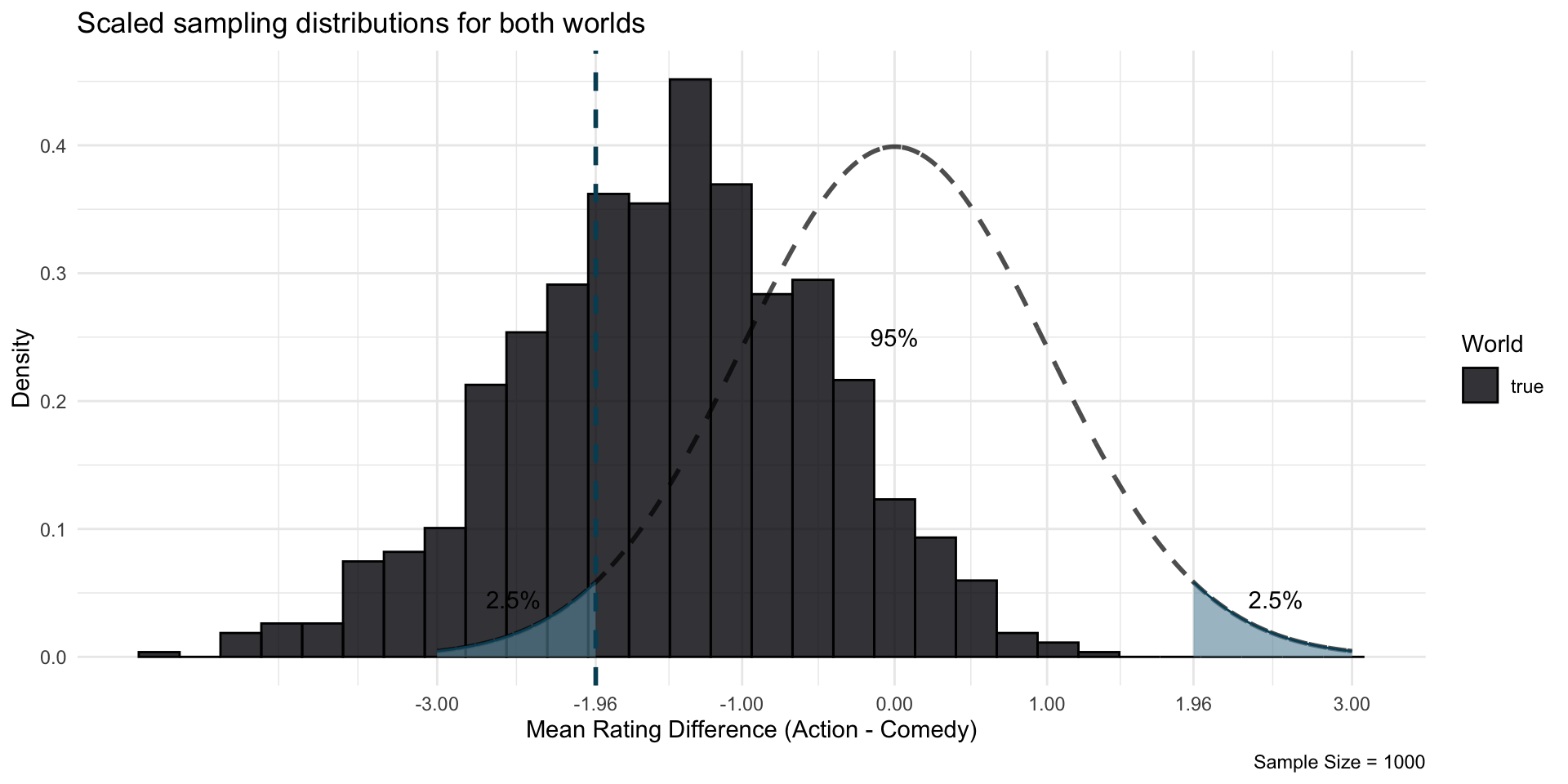
Two errors

Hypothesis Testing
Statistical Power
- Plot your Sampling distribution (use
data.frame()to turn your vector into a data frame that can be read byggplot)
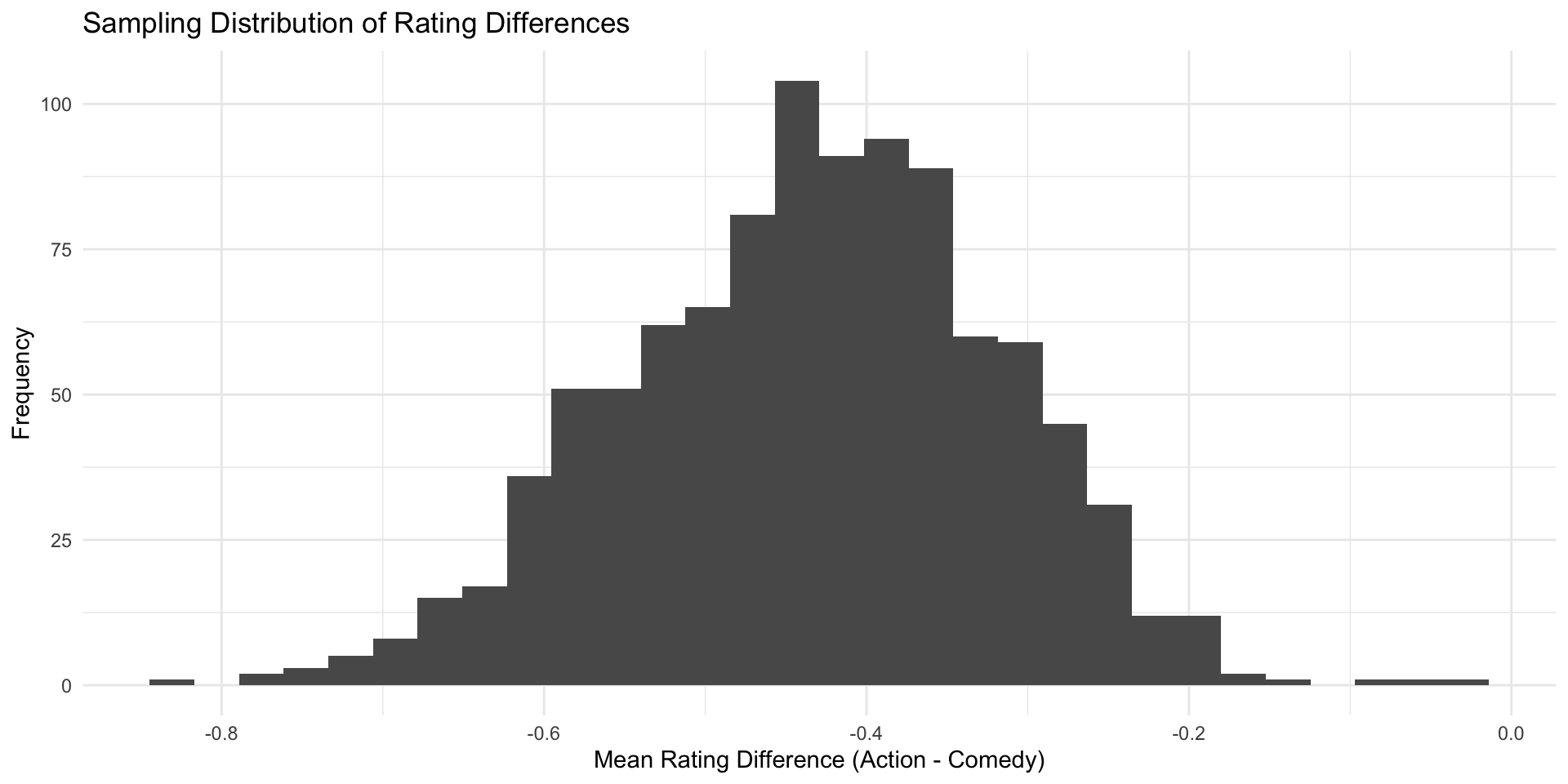
- Check the transformation: plot the new, standardized values
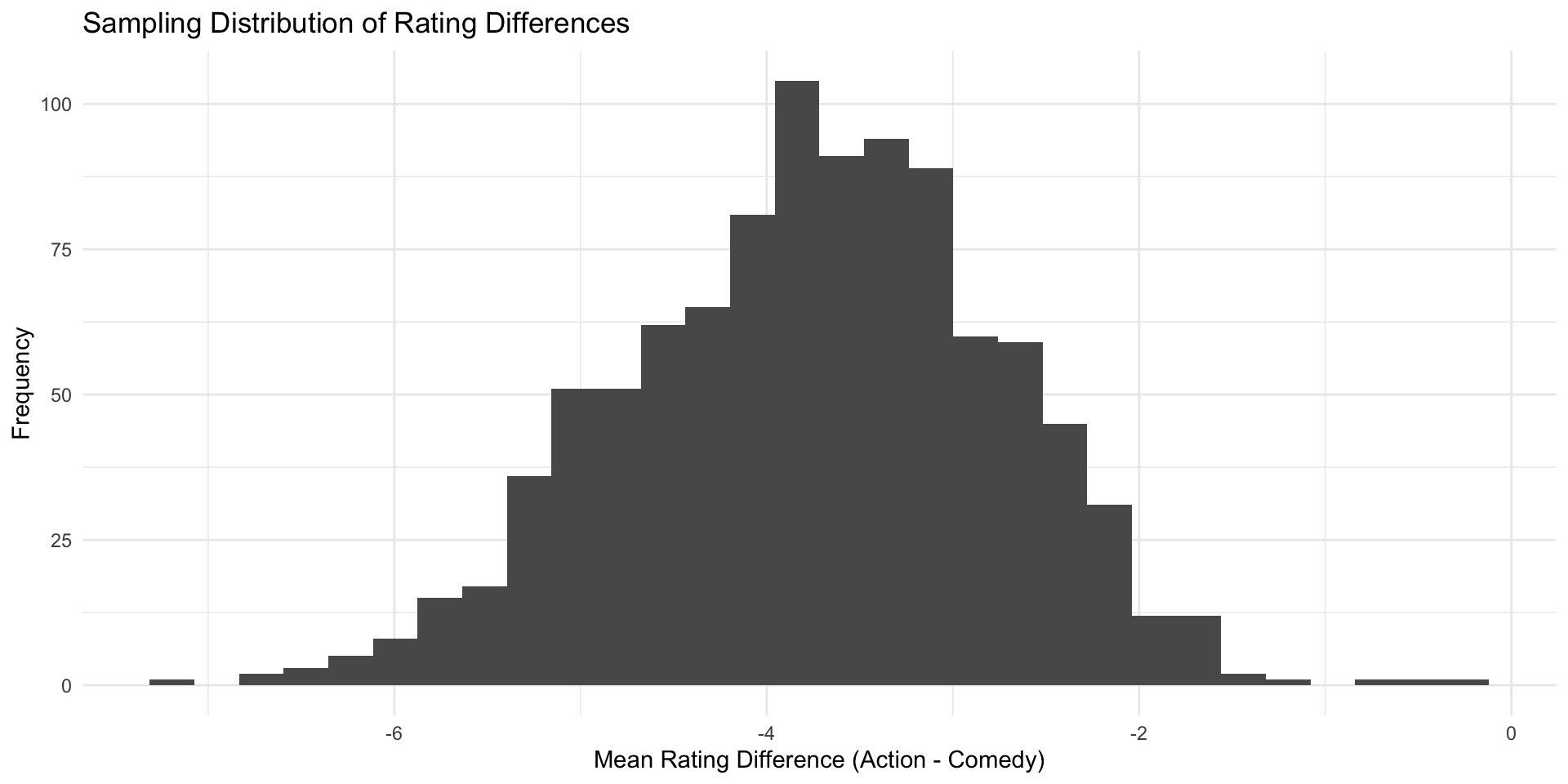
The central limit theorem (again)
The larger the sample size, the more statistical power