4 How wise is the crowd: Can we infer people are accurate and competent merely because they agree with each other?
Abstract
Are people who agree on something more likely to be right and competent? Evidence suggests that people tend to make this inference. However, standard wisdom of crowds approaches only provide limited normative grounds. Using simulations and analytical arguments, we argue that when individuals make independent and unbiased estimates, under a wide range of parameters, individuals whose answers converge with each other tend to have more accurate answers and to be more competent. In 6 experiments (UK participants, total N = 1197), we show that participants infer that informants who agree have more accurate answers and are more competent, even when they have no priors, and that these inferences are weakened when the informants were systematically biased. In conclusion, we speculate that inferences from convergence to accuracy and competence might help explain why people deem scientists competent, even if they have little understanding of science.
published as:
Pfänder, J., De Courson, B., & Mercier, H. (2025). How wise is the crowd: Can we infer people are accurate and competent merely because they agree with each other? Cognition, 255, 106005. https://doi.org/10.1016/j.cognition.2024.106005
For supplementary materials, please refer either to the published version, or the publicly available preprint via github.
4.1 Introduction
Imagine that you live in ancient Greece, and a fellow called Eratostenes claims the circumference of the earth is 252000 stades (approximately 40000 kilometers). You know nothing about this man, the circumference of the Earth, or how one could measure such a thing. As a result, you discard Eratostenes’ opinion and (mis)take him for a pretentious loon. But what if other scholars had arrived at very similar measurements, independently of Eratosthenes? Or even if they had carefully checked his measurement, with a critical eye? Wouldn’t that give you enough ground to believe not only that the estimates might be correct, but also that Eratosthenes and his fellow scholars must be quite bright, to be able to achieve such a feat as measuring the Earth?
In this article, we explore how, under some circumstances, we should, and we do infer that a group of individuals whose answers converge are likely to be correct, and to be competent in the relevant area, even if we had no prior belief about either what the correct answer was, or about these individuals’ competence.
We begin by reviewing existing studies showing that people infer that competent informants who converge in their opinions are likely to be accurate. The wisdom of crowds literature provides normative grounds for this inference. We then argue that both the experimental and theoretical literature have paid little attention to extending this inference to cases in which there is no information about the informants’ competence, and to inferences about the competence of the informants. We first develop normative models, both analytically and with simulations, to show that inferences from convergence to accuracy and to competence are warranted under a wide range of parameters. Second, we present a series of experiments in which participants evaluate both the accuracy and competence of informants as a function of how much their answers converge on a given problem, in the absence of any priors about these individuals’ competence, or what the correct answer is.
4.2 Do people infer that individuals whose answers converge tend to be right, and to be competent?
The literature on the wisdom of crowds has treated separately situations with continuous answers, such as the weight of an ox in Galton’s famous observation (Galton 1907), and with categorical answers, as when voters have to choose between two options, in the standard Condorcet Jury Theorem (De Condorcet 2014). The continuous and the categorical case are typically modeled with different tools, and they have usually been studied in different empirical literatures (see below). Given that they both represent common ways for answers to converge more or less (e.g. when people give numerical estimates vs. vote on one of a limited number of options), we treat them both here, with different simulations and experiments.
In the continuous case, the most relevant evidence comes from the literature on ‘advice-taking’ (for review, see, Kämmer et al. 2023). In these experiments, participants are called ‘judges’ who need to make numerical estimates–sometimes on factual knowledge, e.g. ‘What year was the Suez Canal opened first?’ (Yaniv 2004), sometimes on knowledge controlled by the experimenters, e.g. ‘How many animals were on the screen you saw briefly?’ (Molleman et al. 2020). To help answer these questions, participants are given estimates from others, the ‘advisors’.
Most of this literature is irrelevant to the point at hand since participants are presented with single estimates, either from a single advisor (e.g. Bednarik and Schultze 2015; Soll and Larrick 2009; Yaniv 2004; Yaniv and Kleinberger 2000; Harvey and Fischer 1997), or as an average coming from a group of advisors (e.g. Jayles et al. 2017; Mannes 2009), but without any information about the distribution of initial estimates, so that we cannot tell whether participants put more weight on more convergent answers.
Some advice-taking studies provide participants with a set of individual estimates. One subset of these studies manipulates the degree of convergence between groups of advisors, through the variance of estimates (Molleman et al. 2020; Yaniv, Choshen-Hillel, and Milyavsky 2009), or their range (Budescu and Rantilla 2000; Budescu et al. 2003; Budescu and Yu 2007). These studies find that participants are more confident about, or rely more on, estimates from groups of advisors that converge more.
Other studies manipulated the degree of convergence within a group of advisors. These studies present participants with a set of estimates, some of which are close to each other, while others are outliers (Harries, Yaniv, and Harvey 2004; Yaniv 1997, study 3 & 4). These studies find that participants discount outliers when aggregating estimates.
Studies on advice taking thus suggest participants believe that more convergent opinions are more likely to be correct. None of these studies investigated whether participants also believe that those whose opinions converge are also more likely to possess greater underlying competence.
In categorical choice contexts, there is ample and long-standing (e.g. Crutchfield 1955) evidence from experimental psychology that participants are more likely to be influenced by majority opinions, and that this influence is stronger when the majority is larger, both in absolute and in relative terms (e.g., Morgan et al. 2012; for review, see Mercier and Morin 2019). This is true even if normative conformity (when people follow the majority because of social pressure rather than a belief that the majority is correct) is unlikely to play an important role (e.g. because the answers are private, see Asch 1956). Similar results have been obtained with young children (e.g. Fusaro and Harris 2008; Corriveau, Fusaro, and Harris 2009; Bernard et al. 2015; Bernard, Proust, and Clément 2015; E. E. Chen, Corriveau, and Harris 2013; Herrmann et al. 2013; Morgan, Laland, and Harris 2015).
If many studies have demonstrated that participants tend to infer that more convergent answers are more likely to be correct, few have examined whether participants thought that this convergence was indicative of the informants’ competence. One potential exception is a study with preschoolers in which the children were more likely to believe the opinion of an informant who had previously been the member of a majority over that of an informant who had dissented from the majority (Corriveau, Fusaro, and Harris 2009). However, it is not clear whether the children thought the members of the majority were particularly competent, since their task–naming an object–was one in which children should already expect a high degree of competence from (adult) informants. This result might thus indicate simply that children infer that someone who disagrees with several others on how to call something is likely wrong, and thus likely less competent at least in that domain.
4.3 What inferences from convergence should we expect people to draw?
Should we expect that people be able to infer that more convergent answers likely indicate not only more accurate answers, but also that those who gave the answers were competent? In order to make the best of communicated information, humans have to be able to evaluate it, so as to discard inaccurate or harmful information, while accepting accurate and beneficial information (Smith and Harper 2003). It has been argued that a suite of cognitive mechanisms–mechanisms of epistemic vigilance–evolved to serve this function (Sperber et al. 2010; Mercier 2020). Since the opinion of more than one individual is often available to us, there should be mechanisms of epistemic vigilance dedicated to processing such situations. It would be these mechanisms that lead us to put more weight on an opinion that is shared by a larger majority (in relative or absolute terms), and, in some cases at least, to discount majority opinion when the opinions haven’t been formed independently of each other (Mercier and Miton 2019). Evidence suggests that these mechanisms rely on heuristics which become more refined with age (Morgan, Laland, and Harris 2015), and which are far from perfect (in particular, they ignore many cases of informational dependencies, see, e.g. Yousif, Aboody, and Keil 2019; Mercier and Miton 2019). As mentioned above, in the experiments evaluating how people process convergent information, the participants had grounds to believe that the information came from competent informants. However, the same mechanisms could lead people to perform the same inference when they do not have such information (especially since, as is shown presently, such an inference is warranted).
Regarding the inference from convergence to competence, other cognitive mechanisms allow us to infer how competent people are, based on a variety of cues, from visual access (Pillow 1989), to the time it takes to answer a question (Richardson and Keil 2022). One of the most basic of these mechanisms infers from the fact that someone was right, that they possess some underlying competence (e.g. Koenig, Clément, and Harris 2004). As a result, if participants infer that convergent opinions are more likely to be accurate, they should also infer that the informants who provided the opinions are competent. Before testing whether participants infer accuracy and competence from convergence, we show that these inferences are normatively warranted, both in the categorical and in the continuous case.
4.3.1 Analytical argument
Regarding the analytical answer, the question can be broken down into two questions. First, can we infer that a population of informants whose answers converge more is, on average, more competent? Second, can we infer that, within this population, individuals who are closer to the consensus or to the average answer are more competent?
In the continuous case, let us imagine a population of informants. Individual opinions are drawn from a normal distribution, centered on the correct answer (i.e., informants have no systematic bias, as for instance in Galton’s classic demonstration, Galton 1907). The variance of this distribution represents the individuals’ competence: the larger the variance, the lower the competence. We observe the individual answers. In this setting, it is well known in statistics (see also Electronic Supplementary Materials, ESM) that the sample mean (i.e. the mean of the answers of all the informants) is the best estimator of the correct answer, and the sample variance (i.e. the mean squared distance between the answers and the sample mean) is the best estimator of the population’s average competence (best understood here as the least volatile estimator). This means that a population of informants whose answers converge more (lower sample variance) is, on average, more competent (informants tend to answer with a lower variance).
We can extend this argument from populations to individuals: Consider that competence varies within a population, such that each informant’s answer is drawn from their own distribution – always centered on the correct answer, but with different variances. In this case, the distance between each informant’s answer and the sample mean provides the best estimate of that informant’s competence (i.e. individuals whose answers are further away from the sample mean tend to be less competent).
In the categorical case, we define the competence of an informant as the probability of choosing the correct answer. The law of large numbers implies that the relative size of the majority – the share of informants who choose the most chosen answer – is, when the population is large enough, a good approximation of the average competence of the population (e.g. if the average competence is .66, and there are enough informants, then approximately 66% of informants will select the right answer). For smaller populations, the relationship holds, with some degree of noise. In other words, the more the answers converge, the more the population can be inferred to be competent (and the larger the population, the more reliable the inference).
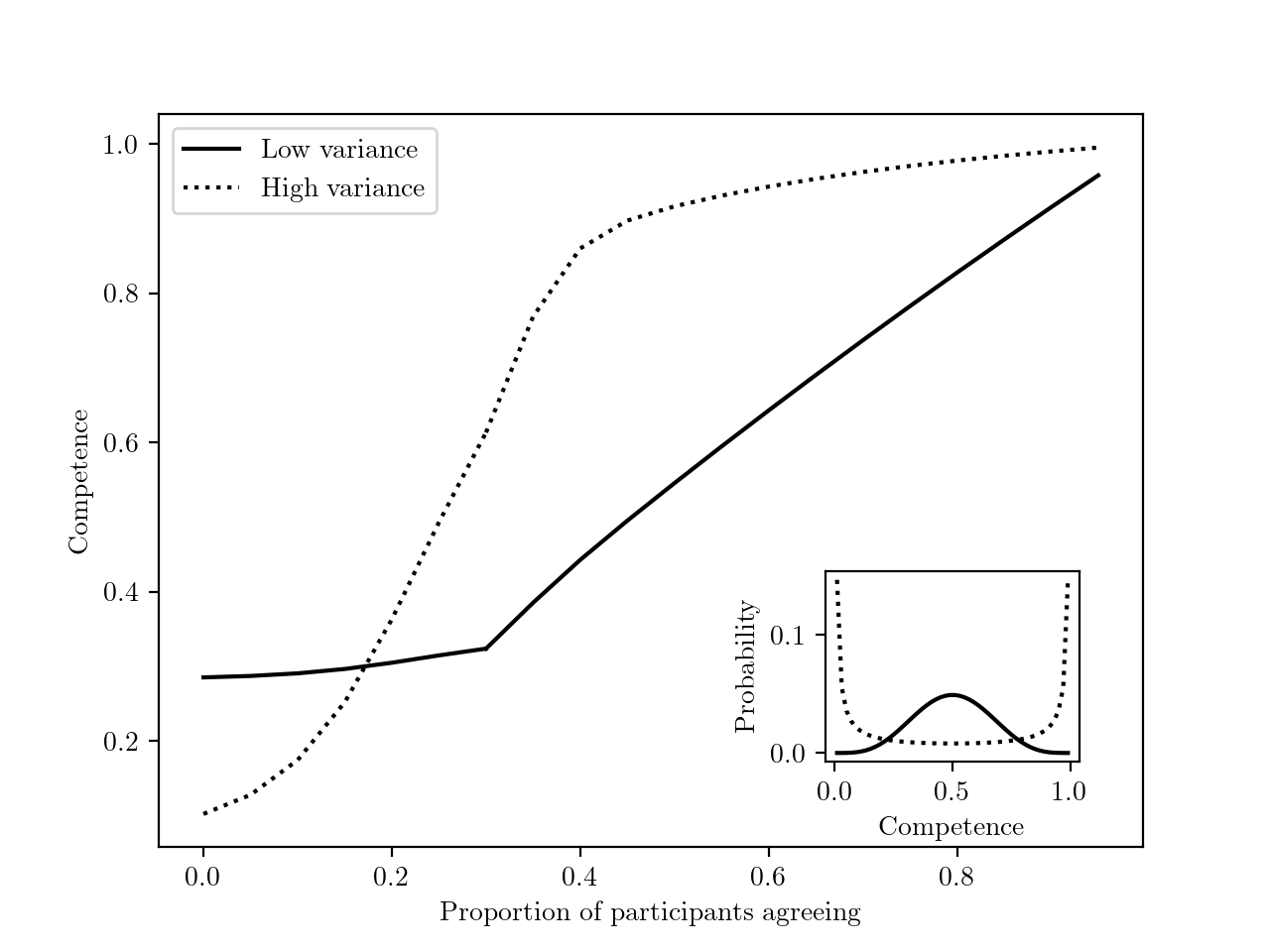
Now, can we infer that informants belonging to the majority are more competent? To do so, we must assume some distribution of competence in the population. Using Bayes theorem, we can then show (see ESM) that the more informants agree with a focal informant, the more the focal informant can be inferred to be competent (Figure 4.1). We also find that, the more competence varies in the population, the more the degree of convergence is indicative of an informant’s competence. For example, if competence is roughly uniform in the population, then being part of a minority likely reflects bad luck, rather than incompetence. More generally, the fact that the focal individual is right (their ‘accuracy’) can be inferred more strongly than their competence, as there is noise in the answer choice (an incompetent individual can always pick the correct answer by chance and vice versa). Figure 4.1) provides an example with a specific categorical choice scenario, under two different population distributions of competence.
4.3.2 Simulations
In order to better understand the influence of different parameters (e.g. degree of convergence, number of individuals) on the relationship between convergence, accuracy, and competence of informants, we conducted simulations. In all simulations, we assume agents to be unbiased and independent in their answers, but varying in their competence. All code and data regarding the simulations can be found on Open Science Framework project page (https://osf.io/6abqy/).
4.3.2.1 Continuous case
Groups of agents, with each agents’ competence varying, provide numerical answers. We measure how accurate these answers are, and how much they converge (i.e. how low their variance is). We then look at the relationship between convergence and both the accuracy of the answers and the competence of the agents.
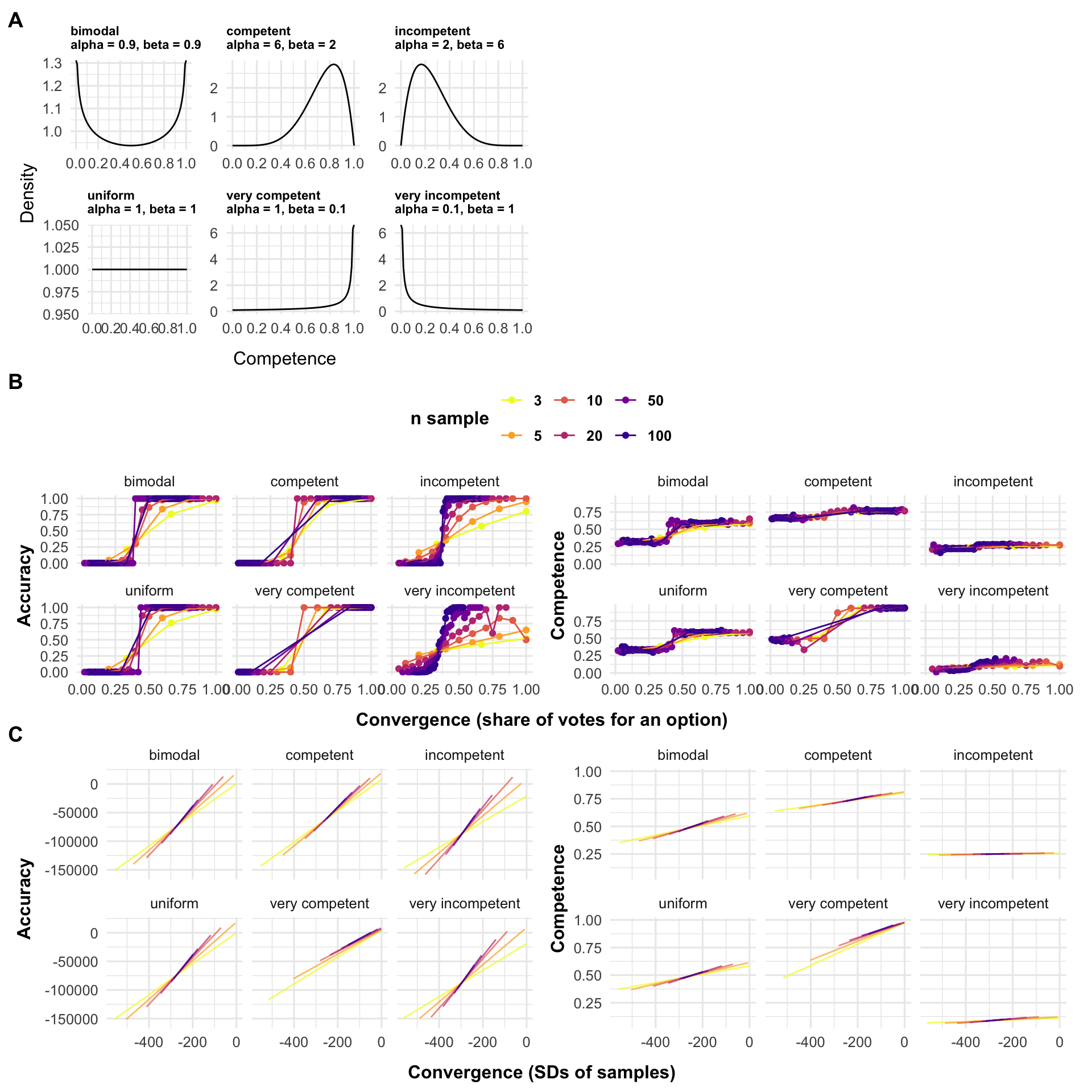
More specifically, agents provide an estimate on a scale from 1000 to 2000 (chosen to match the experiments below). Each agent is characterized by a normal distribution of possible answers. All of the agents’ distributions are centered around the correct answer, but their standard deviation varies, representing varying degrees of competence. The agents’ standard deviation varies from 1 (highest competence) to 1000 (lowest competence). Each agent’s competence is drawn from a population competence distribution, expressed by a beta distribution, which can take different shapes. We conducted simulations with a variety of beta distributions which cover a wide range of possible competence populations (see Figure 4.2 A).
A population of around 990000 agents (varying slightly as a function of group sizes) with different competence levels is generated. An answer is drawn for each agent, based on their respective competence distribution. The accuracy of this answer is defined as the squared distance to the true answer. Having a competence and an accuracy value for each agent, we randomly assign agents to groups of, e.g., three. For each group, we calculate the average of the agents’ competence and accuracy. We measure the convergence of a group’s answers by calculating the standard deviation of the agents’ answers. We repeat this process for different sample sizes for the groups, and different competence distributions. Figure 4.2 C displays the resulting relation of convergence with accuracy (left), and competence (right) for different underlying competence distributions and group sizes. We draw broad conclusions from these results after reporting the outcome of the simulations with categorical answers.
4.3.2.2 Categorical case
In the case of categorical answers, convergence can be measured as the relative size of informants picking the same option. The Condorcet jury theorem (De Condorcet 2014; for a recent treatment, see Dietrich and Spiekermann 2013) and its extensions to situations with more than two options (e.g., Hastie and Kameda 2005) already shows that the answer defended by the majority/plurality is more likely to be correct. Regarding competence, Romeijn and Atkinson (2011) have shown that when individuals are more competent, the share of the majority vote tends to increase. However, they have only studied a case with a uniform distribution of competence. By contrast, here, we investigate a wide range of distributions of competence, and we do not assume that all individuals are equally competent, meaning that, from an observed set of answers, we can attribute an average competence to individuals whose answers form a majority/plurality vs. individuals whose answers form a minority.
We simulate agents whose competence varies and who have to decide between a number of options, one of which is correct. Competence is defined as a value p which corresponds to the probability of selecting the right answer (the agents then have a probability (1-p)/(m-1), with m being the number of options, of selecting any other option). Competence values range from chance level (p = 1/m) to always selecting the correct option (p = 1). Individual competence levels are drawn from the same population competence beta distributions as in the numerical case (see Figure 4.2 A). Based on their competence level, we draw an answer for each agent. We measure an agent’s accuracy as a binary outcome, namely whether they selected the correct option or not. In each simulation around 99900 agents (varying slightly as a function of the group size) are generated, and then randomly assigned to groups (of varying size in different simulations). Within these groups, we first calculate the share of individuals voting for each answer, allowing us to measure convergence. For example, in a scenario with three choice options and three individuals, two might vote for option A, and one for option C, resulting in two levels of convergence, \(2/3\) for A and \(1/3\) for C. For each level of convergence occurring within a group, we then compute (i) the accuracy (either 1 if the correct option or 0 else), (ii) the average competence of agents. Across all groups, we then compute the averages of these values, for each level of convergence.
We repeat this procedure varying population competence distributions and the size of informant groups, holding the number of choice options constant at n = 3 (for simulations with varying choice options, see ESM). Figure 4.2 B shows the average accuracy (left), and the average competence (right) value as a function of convergence, across different underlying competence distributions and group sizes.
The simulations for the numerical and categorical case demonstrate a similar pattern, which can be summarized as follows:
- Irrespective of group size (and number of choice options) and of the competence distribution, there is a very strong relation between convergence and accuracy: more convergent answers tend to be more accurate.
- For any group size and any competence distribution, there is a relation between convergence and the competence of the agents: more convergent answers tend to stem from more competent agents. The strength of this relation is not much affected by the number of agents whose answers are converging, but, although it is always positive, it ranges from very weak to very strong depending on the population’s competence distribution.
- The relation between convergence and accuracy is always much stronger than the relation between convergence and competence of the agents.
4.4 Overview of the experiments
Our models indicate that groups of informants are more likely to have given accurate answers, and to be competent, when their answers converge. In a series of experiments, we test whether people draw these inferences both in numerical tasks (Experiments 1, 2, 3), and in categorical tasks (Experiments 4, 5, 6). By contrast with previous studies, participants were not given any information about the tasks–how difficult they were–and the informants–how competent they might be. There has recently been much interest in investigating whether participants are able to take informational dependencies into account when evaluating convergent information (Yousif, Aboody, and Keil 2019; Mercier and Miton 2019; Desai, Xie, and Hayes 2022; Xie and Hayes 2022; Yin et al. 2024). To test whether participants took into account dependencies between the informants in the present context, this factor was manipulated in two different ways (in Experiment 2, some informants had discussed with each other; in Experiments 3 and 5, some informants had an incentive to provide the same answer). We predicted that dependencies between the informants’ answers should reduce participants’ reliance on the convergence of the answer as a cue to accuracy and to competence.
All experiments were preregistered. All documents, data and code can be found on Open Science Framework project page (https://osf.io/6abqy/). All analyses were conducted in R (version 4.2.2) using R Studio. For most statistical models, we relied on the lme4 package and its lmer() function. Unless mentioned otherwise, we report unstandardized model coefficients that can be interpreted in units of the scales we use for our dependent variables.
4.5 Experiment 1
In Experiment 1, participants were provided with a set of numerical estimates which were more or less convergent, and asked whether they thought the estimates were accurate, and whether the informants making the estimates were competent. Perceptions of accuracy were measured as the confidence in what the participants thought the correct answer was, on the basis of the numerical estimates provided: the more participants think they can confidently infer the correct answer, the more they must think the estimates accurate, on average (the results replicate with a more direct measure of accuracy, see Experiment 3). Our hypotheses were:
H1: When making a guess based on the estimates of (independent) informants, participants will be more confident about their guess when these estimates converge compared to when they diverge.
H2: Participants perceive (independent) informants whose estimates converge more as more competent than informants whose estimates diverge.
We had three research questions regarding the number of informants which report in the ESM.
4.5.1 Methods
4.5.1.1 Participants
We recruited 200 participants from the UK via Prolific (100 female, 100 male; \(age_\text{mean}\): 39.73, \(age_\text{sd}\): 15.39, \(age_\text{median}\): 35.5). Not a single participant failed our attention check. The sample size was determined on the basis of a power analysis for a t-test to detect the difference between two dependent means (“matched pairs”) run on G*Power3. The analysis suggested that a combined sample of 199 would provide us with 80% power to detect a true effect size of Cohen’s d \(\geq\) 0.2 (alpha = .05, two-tailed).
4.5.1.2 Procedure
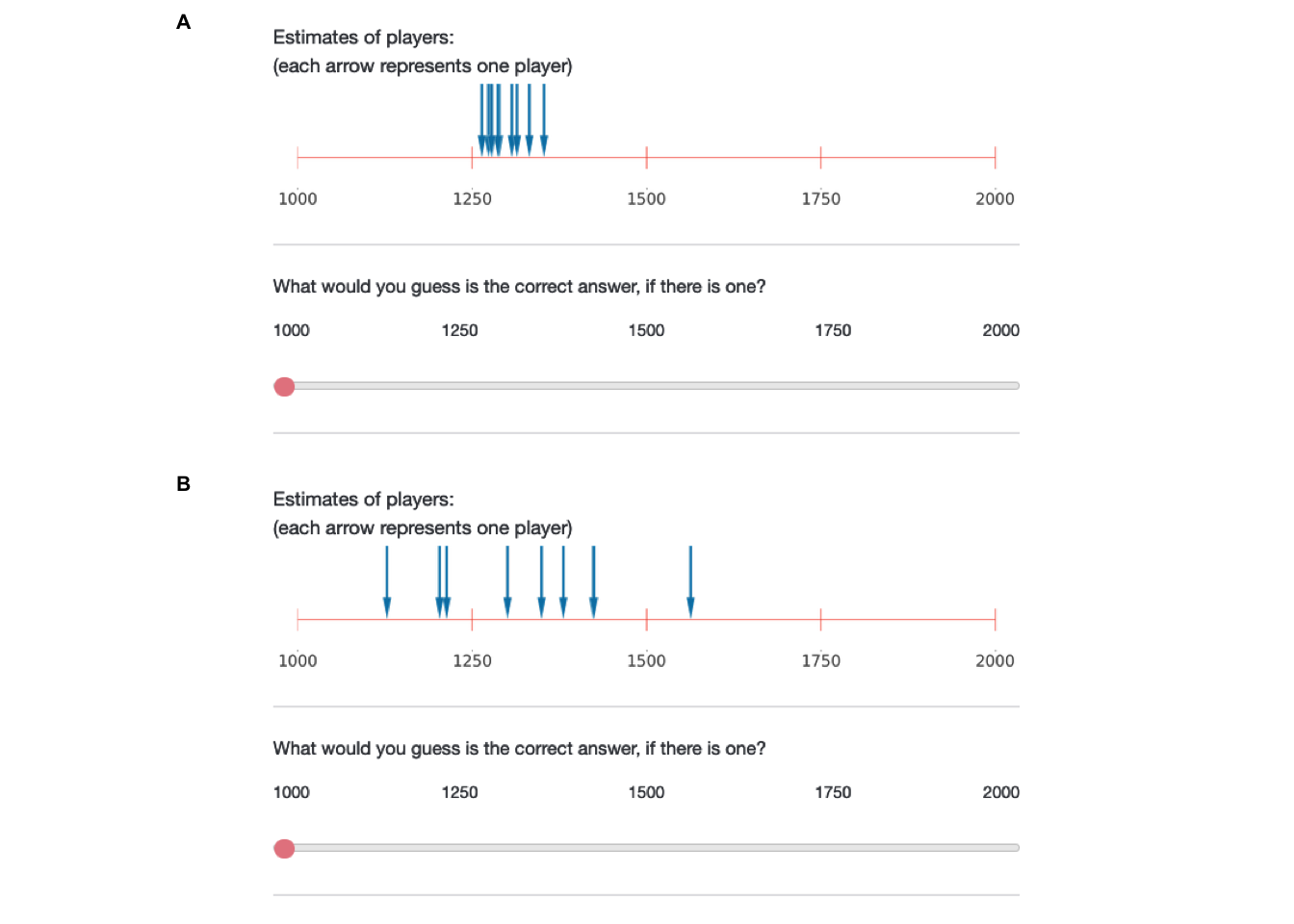
After providing their consent to participate in the study and passing an attention check, participants read the following introduction: “Some people are playing games in which they have to estimate various quantities. Each game is different. You have no idea how competent the people are: they might be completely at chance, or be very good at the task. It’s also possible that some are really good while others are really bad. Some tasks might be hard while others are easy. Across various games, we will give you the answers of several players, and ask you questions about how good they are. As it so happens, for all the games, the estimates have to be between 1000 and 2000, but all the games are completely different otherwise, and might require different skills, be of different difficulties, etc. Each player in the game makes their own estimate, completely independent of the others”. After being presented with the results of a game (Figure 4.3), participants had to (i) make a guess about the correct answer based on the estimates they see, “What would you guess is the correct answer, if there is one?”, (ii) estimate their confidence in this guess, “How confident are you that your answer is at least approximately correct?” on a 7-point Likert scale (“not confident at all” to “extremely confident”), (iii) estimate the competence of the group of players whose estimates they saw, “On average, how good do you think these players are at the game?”, also on a 7-point Likert scale (from “not good at all” to “extremely good”).
4.5.1.3 Design
We manipulated two experimental factors, with two levels each: the convergence of the estimates (how close they were to each other; levels: divergent/convergent), and the number of estimates (how many players there were; levels: three/ten). This latter factor was chiefly included to make our results more robust, and was not attached to specific hypotheses. We used a 2 (convergence: divergent/convergent) x 2 (number: three/ten) within-participant design, with each participant seeing all the conditions. Participants saw two different sets of estimates per condition, for a total of eight sets of estimates per participant.
4.5.1.4 Materials
We generated sets of estimates with random draws from normal distributions. First, we varied the standard deviation of these distributions to simulate the degree of convergence (150 for divergence, 20 for convergence; estimate scale ranged from 1000 to 2000). Second, we varied the number of draws (either three or ten) from these distributions. For each of the four possible resulting conditions, we generated two random draws. We repeated this process for three different sets of estimates, and participants were randomly assigned to one of these sets. More information on how the stimuli were created can be found in the ESM.
4.5.2 Results and discussion
To account for dependencies of observations due to our within-participant design, we ran mixed models, with a random intercept and a random slopes of convergence for participants. In the models for our hypotheses, we control for the number of estimates provided to the participants (three or ten). Visualizations and descriptive statistics can be found in ESM. We find a positive effect of convergence on accuracy: Participants were more confident about their estimate in convergent scenarios (mean = 4.56, sd = 1.448) than in divergent ones (mean = 3.192, sd = 1.392; \(\hat{b}_{\text{Accuracy}}\) = 1.368 [1.225, 1.51], p < .001). We also find a positive effect of convergence on competence: participants rated players as more competent in convergent scenarios (mean = 4.75, sd = 1.237) than in divergent ones (mean = 3.518, sd = 1.266; \(\hat{b}_{\text{Competence}}\) = 1.232 [1.065, 1.4], p < .001).
In an exploratory, non-preregistered analysis, we tested whether the effect of convergence is larger on accuracy than on competence. To this end, we regressed the outcome score on convergence and its interaction with a binary variable indicating which outcome was asked for (accuracy or competence), while controlling for the number of informants. We do not find a statistically significant interaction that would indicate a difference of the effect of convergence (\(\hat{b}\) = 0.135 [-0.001, 0.271], = 0.052). Pooled across divergent and convergent conditions, we find that participants reported lower perceived accuracy than competence (\(\hat{b}\) = -0.257 [-0.359, -0.156], < .001)
In summary, as predicted, when the informants’ answers were more convergent, participants were more confident that their answers were correct, and they believed the informants to be more competent. This was true both when there were three informants and when there were ten informants.
4.6 Experiment 2
We have shown that it is rational to infer that convergent estimates are more likely to be accurate, and to have been made by competent individuals, only if these individuals were independent and unbiased. However, convergence could come about differently. If the individuals do not make their estimates independently of each other, a single individual might exert a strong influence on the others, making their convergence a poor cue to their accuracy. Alternatively, all individuals might have an incentive to provide a similar, but not accurate answer. In Experiment 2, we investigate the first possibility, and the second in Experiment 3. In particular, for Experiment 2 we rely on past results showing that participants, under some circumstances, put less weight on opinions that have been formed through discussion, by contrast with more independent opinions (Harkins and Petty 1987; see also Lopes, Vala, and Garcia-Marques 2007; Hess and Hagen 2006; Einav 2018). We sought to replicate this finding in the context of convergent estimates, formulating the following hypotheses:
H1: When making a guess based on convergent estimates of informants, participants will be more confident about their guess when informants were independent compared to when they weren’t (i.e. they could discuss before).
H2: Participants perceive informants whose estimates converge as more competent when they are independent, compared to when they weren’t (i.e. they could discuss before).
Note that these predictions only stem from past empirical results, and are not necessarily normatively justified (modeling the effects of discussion would be beyond the scope of this paper, but see Dietrich and Spiekermann 2024).
4.6.1 Methods
4.6.1.1 Participants
We recruited 200 participants from the UK via Prolific (100 female, 99 male, 1 not-identified; \(age_\text{mean}\): 40.545, \(age_\text{sd}\): 13.561, \(age_\text{median}\): 38.5). Not a single participant failed our attention check. As for experiment 1, the sample size was determined on the basis of a power analysis for a t-test to detect the difference between two dependent means (“matched pairs”) run on G*Power3. The analysis suggested that a combined sample of 199 would provide us with 80% power to detect a true effect size of Cohen’s d \(\geq\) 0.2 (alpha = .05, two-tailed).
4.6.1.2 Design
In a within-participants design, participants saw both an independence condition, in which they were told “Players are asked to make completely independent decisions – they cannot see each other’s estimates, or talk with each other before giving their estimates,” and a dependence condition, in which they were told “Players are asked to talk with each other about the game at length before giving their estimates.”
4.6.1.3 Materials
We used the materials generated for the convergent condition of Experiment 1. By contrast to Experiment 1, participants saw only two stimuli in total (one set of estimates per condition), and we only used stimuli involving groups of three informants. Otherwise, we proceeded just as in Experiment 1: we randomly assigned individual participants to one of the three series of stimuli, and for each participant, we randomized the order of appearance of conditions.
4.6.2 Results and discussion
To account for dependencies of observations due to our within-participant design, we ran mixed models, with a random intercept for participants. Visualizations and descriptive statistics can be found in ESM. The data does not support our hypotheses. Participants were slightly less confident about their estimates when the converging informants were independent (mean = 3.775, sd = 1.502), compared to when they discussed (mean = 4.03, sd = 1.389; \(\hat{b}_{\text{Accuracy}}\) = -0.255 [-0.462, -0.048], p = 0.016). The effect is small, but in the opposite direction of what we had predicted. We do not find an effect regarding competence (\(\hat{b}_{\text{Competence}}\) = -0.12 [-0.272, 0.032], p = 0.120).
Contrary to the hypotheses, participants did not deem convergent estimates made after a discussion, compared to independently made estimates, to be less accurate, or produced by less competent individuals. This might stem from the fact that participants, in various situations, neglect informational dependencies (Yousif, Aboody, and Keil 2019), or from the fact that discussing groups actually perform better than non-discussing groups in a range of tasks (for review, see, e.g., Mercier 2016), including numerical estimates (e.g. Mercier and Claidière 2022). As a result, the participants in the current experiment might have been behaving rationally when they did not discount the estimates made after discussion.
4.7 Experiment 3
Experiment 3 tests whether participants are sensitive to another potential source of dependency between convergent estimates: when the individuals making the estimate share an incentive to bias their estimates and disregard accuracy. Even though Experiment 3 is formally similar to Experiment 1, the setting is different, as participants were told that they would be looking at (fictional) predictions of experts for stock values, instead of the answers of individuals in abstract games. In the conflict of interest condition, the experts had an incentive to value the stock in a given way, while they had no such conflict of interest in the independence condition. We tested for an interaction, namely whether the positive effect of convergence is reduced when informants are systematically biased, compared to when they are not. On this basis, we formulate four hypotheses, two of which are identical to those of Experiment 1, and only apply in the independent condition, and two that bear on the interaction:
H1a: Participants perceive predictions of independent informants as more accurate when they converge compared to when they diverge.
H1b: Participants perceive independent informants as more competent when their predictions converge compared to when they diverge.
H2a: The effect of convergence on accuracy (H1a) is more positive in a context where informants are independent compared to when they are in a conflict of interest.
H2b: The effect of convergence on competence (H1b) is more positive in a context where informants are independent compared to when they are in a conflict of interest.
We have not conducted simulations to validate these predictions. However, given the operationalization chosen, in which convergence should provide little evidence of either accuracy or competence, we believe the predictions regarding the superiority of the independent informants stem naturally from the model of independent informants presented above.
4.7.1 Methods
4.7.1.1 Participants
The interaction design of our third experiment made the power analysis more complex and less standard than for experiments one and two. Because we could build upon data from the first experiment, we ran a power analysis by simulation. The simulation code is available on the OSF, and the procedure is described in the preregistration document. The simulation suggested that 100 participants provide a significant interaction term between 95% and 97% of the time, given an alpha threshold for significance of 0.05. Due to uncertainty about our effect size assumptions and because we had resources for a larger sample, we recruited 199 participants for this study – again, from the UK and via Prolific (99 female, 100 male; \(age_\text{mean}\): 40.296, \(age_\text{sd}\): 12.725, \(age_\text{median}\): 38).
4.7.1.2 Procedure
After providing their consent to participate in the study and passing an attention check, participants read the following introduction: “You will see four scenarios in which several experts predict the future value of a stock. You have no idea how competent the experts are. It’s also possible that some are really good while others are really bad. As it so happens, in all scenarios, the predictions for the value of the stock have to lie between 1000 and 2000. Other than that, the scenarios are completely unrelated: it is different experts predicting the values of different stocks every time.” Participants then saw the four scenarios, each introduced by a text according to the condition the participant was assigned to. To remove any potential ambiguity about participants’ inferences on the accuracy of the estimates, we replaced the question about confidence to one bearing directly on accuracy: “On average, how accurate do you think these three predictions are?” on a 7-point Likert scale (“not accurate at all” to “extremely accurate”). The question about competence read: “On average, how good do you think these three experts are at predicting the value of stocks?”, also assessed on a 7-point Likert scale (from “not good at all” to “extremely good”).
4.7.1.3 Design
We manipulated two factors: informational dependency (two levels, independence and conflict of interest; between participants) and convergence (two levels, convergence and divergence; within participants). In the independence condition, the participants read “Experts are independent of each other, and have no conflict of interest in predicting the stock value - they do not personally profit in any way from any future valuation of the stock.” In the conflict of interest condition, the participants read “All three experts have invested in the specific stock whose value they are predicting, and they benefit if other people believe that the stock will be valued at [mean of respective distribution] in the future.”
4.7.1.4 Materials
The distributions presented were similar to those of Experiment 1, although generated in a slightly different manner (see ESM). Each participant rated four scenarios, two for each level of convergence. By contrast to Experiment 1, all scenarios only involved groups of three informants.
4.7.2 Results and discussion
To account for dependencies of observations due to our within-participant design, we ran mixed models, with a random intercept and a random slope for convergence for participants. We find evidence for all four hypotheses. As for the first set of hypotheses, to match the setting of experiment one, we reduced the sample of Experiment 3 to half of the participants, namely those who were assigned to the independence condition. On this reduced sample, we ran the exact same analyses as in Experiment 1 and replicated the results. As for accuracy, participants rated informants in convergent scenarios (mean = 5.28, sd = 1.052) as more accurate than in divergent ones (mean = 3.4, sd = 1.08; \(\hat{b}_{\text{Accuracy}}\) = 1.88 [1.658, 2.102], p < .001). As for competence, participants rated informants in convergent scenarios (mean = 5.235, sd = 0.992) as more competent than in divergent ones (mean = 3.61, sd = 1.111; \(\hat{b}_{\text{Competence}}\) = 1.625 [1.411, 1.839], p < .001).
The second set of hypotheses targeted the interaction of informational dependency and convergence (Figure 4.4). In the independence condition, the effect of convergence on accuracy was more positive (\(\hat{b}_{\text{interaction, Accuracy}}\) = 0.991 [0.634, 1.348], p < .001) than in the conflict of interest condition (\(\hat{b}_{\text{baseline}}\) = 0.889 [0.636, 1.142], p < .001). Likewise the effect of convergence on competence is more positive (\(\hat{b}_{\text{interaction, Competence}}\) = 0.802 [0.474, 1.13], p < .001) than in the conflict of interest condition (\(\hat{b}_{\text{baseline}}\) = 0.823 [0.591, 1.056], p < .001).
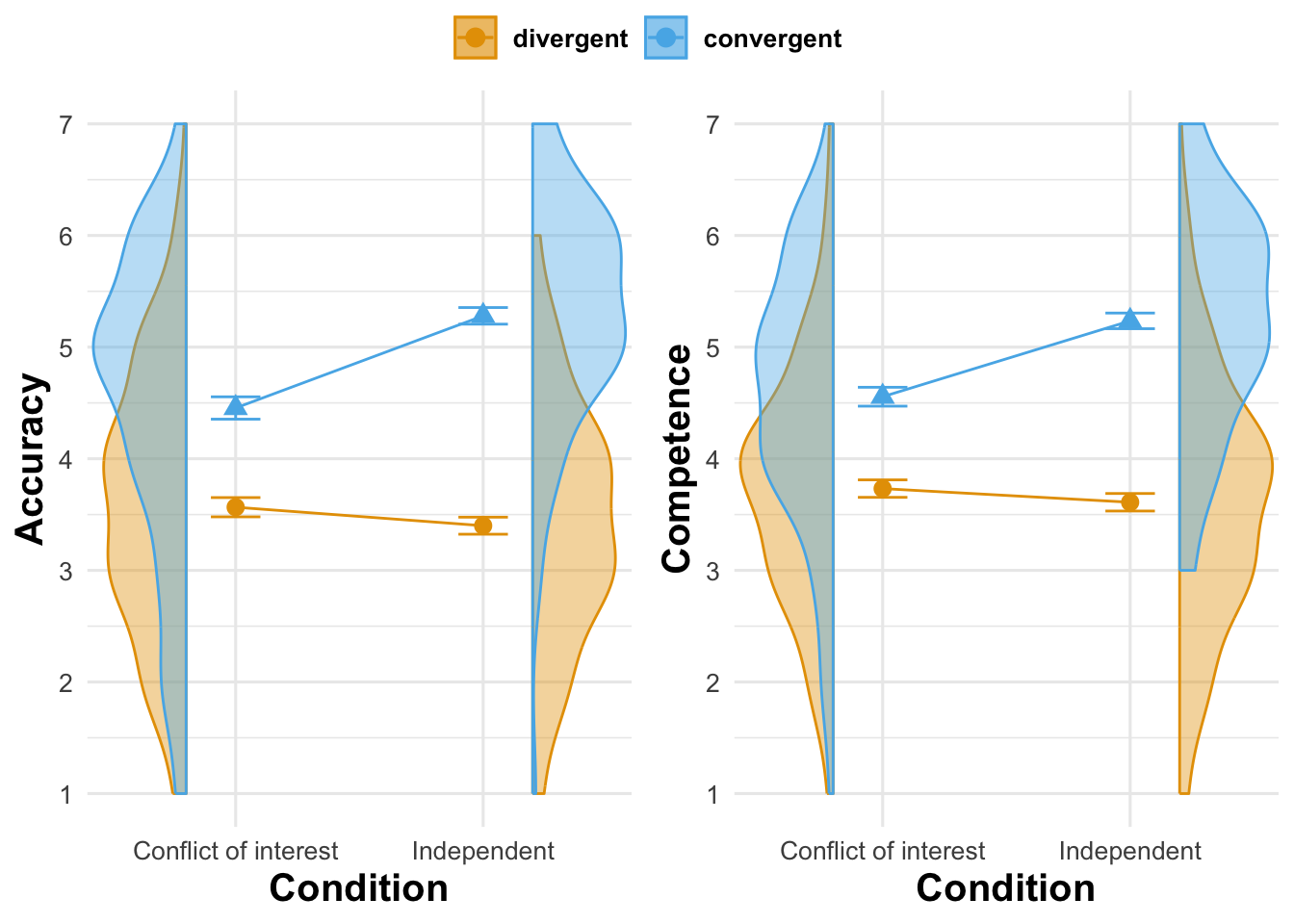
In an exploratory, non-preregistered analysis, we tested whether the effect of convergence is larger on accuracy than on competence. To this end, we regressed the outcome score on convergence and its interaction with a binary variable indicating which outcome was asked for (accuracy or competence), while controlling for informational dependency. We find a negative interaction effect, indicating that pooled across independent and conflict of interest conditions, the effect of convergence had as smaller effect on competence than on accuracy (\(\hat{b}\) = -0.161 [-0.294, -0.028], = 0.018). Pooled across all conditions, participants reported higher perceived competence than accuracy (\(\hat{b}\) = 0.108 [0.025, 0.191], = 0.011).
Experiment 3 shows that, when the individuals making the estimates are systematically biased, participants put less weight on the convergence of their estimates to infer that the estimates are accurate, and that the individuals making them are competent.
4.8 Experiment 4
In a second series of experiments, we test similar predictions to those of the previous experiments, but in a categorical choice context. The set-up is similar to that of Experiment 1, except that the outcomes seen by the participants are not numerical estimates, but choices made between a few options. An additional difference is that participants rate a focal informant, and not a group of informants. There were two reasons for this choice: First, accuracy is not on a continuum as in the first three experiments (an option was either correct or not), so forming an average across informants who chose different options was less sensible. Second, rating a focal individual allowed us to have a minority condition, which would not have been possible when providing an average rating for a group. Experiment 4 tests hypotheses that are analogous to those of Experiment 1:
H1: Participants perceive an estimate of an independent informant as more accurate the more it converges with the estimates of other informants.
H2: Participants perceive an independent informant as more competent the more their estimate converges with the estimates of other informants.
4.8.1 Methods
4.8.1.1 Participants
We ran a power simulation to inform our choice of sample size. All assumptions and details on the procedure can be found on the OSF. We ran two different power analyses, one for each outcome variable. We set the power threshold for our experiment to 90%. The power simulation for accuracy suggested that even for as few as 10 participants (the minimum sample size we simulated data for), we would have a power of close to 100%. The simulation for competence suggested that we achieve statistical power of at least 90% with a sample size of 30. Due to uncertainty about our assumptions and because it was within our budget, we recruited 100 participants, from the UK and via Prolific (50 female, 50; \(age_\text{mean}\): 37.32, \(age_\text{sd}\): 11.526, \(age_\text{median}\): 36).
4.8.1.2 Procedure
After providing their consent to participate in the study and passing an attention check, participants read the following introduction: “To be able to understand the task, please read the following instructions carefully: Some people are playing games in which they have to select the correct answer among three answers. You will see the results of several of these games. Each game is different, with different solutions and involving different players. All players answer independently of each other. At first, you have no idea how competent each individual player is: they might be completely at chance, or be very good at the task. It’s also possible that some players are really good while others are really bad. Some games might be difficult while others are easy. Your task will be to evaluate the performance of one of the players based on what everyone’s answers are.” They were then presented to the results of eight such games (Figure 4.5). To assess perceived accuracy, we asked: “What do you think is the probability of player 1 being correct?”. Participants answered with a slider on a scale from 0 to 100. To assess perceived competence, we asked participants: “How competent do you think player 1 is in games like these?” Participants answered on a 7-point Likert scale (from (1)“not competent at all” to (2)“extremely competent”).
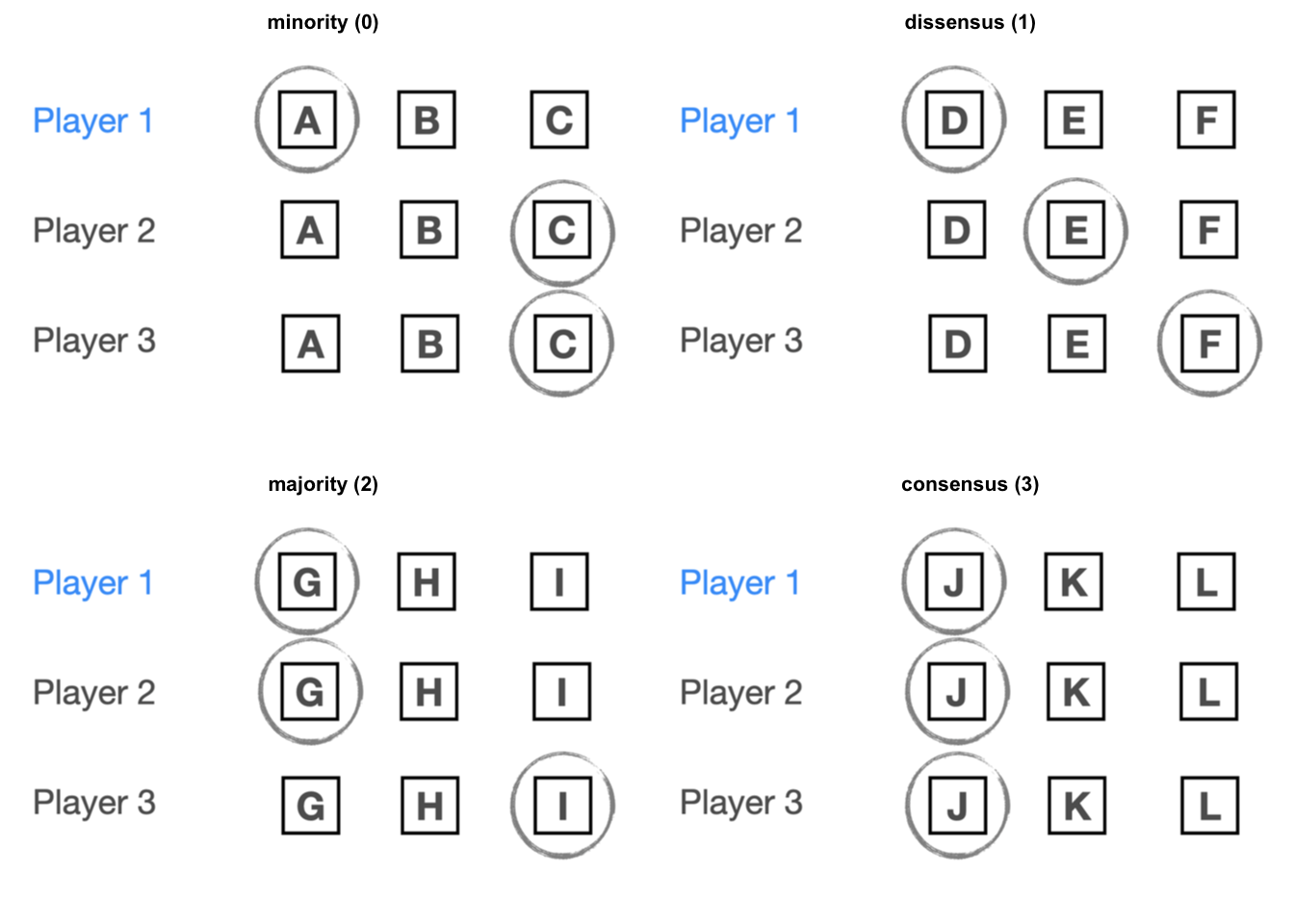
4.8.1.3 Design
We manipulated convergence within participants, by varying the ratio of players choosing the same response as a focal player (i.e. the one that participants evaluate). The levels of convergence are: (i) consensus, where all three players pick the same option [coded value = 3]; (ii) majority, where either the third or second player picks the same option as the first player [coded value = 2]; (iii) dissensus, where all three players pick different options [coded value = 1]; (iv) minority, where the second and third player pick the same option, but one that is different from the first player’s choice [coded value = 0]. In our analysis, we treat convergence as a continuous variable, assigning the coded values in squared parenthesis here.
4.8.1.4 Materials
All participants saw all four conditions, with two stimuli per condition. Each participant therefore saw eight stimuli in total (4 convergence levels x 2 stimuli).
4.8.2 Results and discussion
To account for dependencies of observations due to our within-participant design, we ran mixed models, with a random intercept and a random slope for participants.
As in the numerical setting, we found a positive effect of convergence on both accuracy (\(\hat{b}_{\text{Accuracy}}\) = 16.838 [15.009, 18.668], p < .001; on a scale from 0 to 100) and competence (\(\hat{b}_{\text{Competence}}\) = 0.683 [0.578, 0.788], p < .001; on a scale from 1 to 7).
In the ESM, we show that compared to what the normative models would predict, participants underestimate the effect of convergence on both accuracy and competence, but especially on accuracy.
In an exploratory, non-preregistered analysis, we tested whether the effect of convergence is larger on accuracy than on competence. To do so, we first standardized both outcome scores to account for the different scales. We then regressed the outcome score on convergence and its interaction with a binary variable indicating which outcome was asked for (accuracy or competence). We find a negative interaction, indicating that convergence had a smaller effect on competence than on accuracy (\(\hat{b}\) = -0.095 [-0.136, -0.053], < .001; units in standard deviations).
4.9 Experiment 5
Experiment 5 is a conceptual replication of Experiment 3 in a categorical instead of a numerical case: are participants less likely to infer that more convergent estimates are more accurate, and the individuals who made them more competent, when the estimates are made by individuals with a conflict of interest pushing them to all provide a given answer, compared to when they are made by independent individuals? The independence condition of Experiment 5 also serves as a replication of Experiment 4, leading to the following hypotheses:
H1a: Participants perceive an estimate of an independent informant as more accurate the more it converges with the estimates of other informants.
H1b: Participants perceive an independent informant as more competent the more their estimate converges with the estimates of other informants.
H2a: The effect of convergence on accuracy (H1a) is more positive in a context where informants are independent compared to when they are biased (i.e. share a conflict of interest to pick a given answer).
H2b: The effect of convergence on competence (H1b) is more positive in a context where informants are independent compared to when they are biased (i.e. share a conflict of interest to pick a given answer).
4.9.1 Methods
4.9.1.1 Participants
We ran a power simulation to inform our choice of sample size. All assumptions and details on the procedure can be found on the OSF. We ran two different power analyses, one for each outcome variable. We set the power threshold for both to 90%.
The power simulation for accuracy suggested that for 80 participants, we would have a power of at least 90% for the interaction effect. The simulation for competence suggested that with already 40 participants, we would detect an interaction, but only with 60 participants would we also detect an effect of convergence. Due to uncertainty about our assumptions and because resources were available for a larger sample, we recruited 200 participants, in the UK and via Prolific (99 female, 100, 1 non-identified; \(age_\text{mean}\): 41.88, \(age_\text{sd}\): 13.937, \(age_\text{median}\): 39).
4.9.1.2 Procedure
After providing their consent to participate in the study and passing an attention check, participants read the following introduction: “We will show you three financial advisors who are giving recommendations on investment decisions. They can choose between three investment options. Their task is to recommend one. You will see several such situations. They are completely unrelated: it is different advisors evaluating different investments every time. At first you have no idea how competent the advisors are: they might be completely at chance, or be very good at the task. It’s also possible that some are really good while others are really bad. Some tasks might be difficult while others are easy. Your task will be to evaluate the performance of one of the advisors based on what everyone’s answers are.” To assess perceptions of accuracy, we asked: “What do you think is the probability of advisor 1 making the best investment recommendation?”. Participants answered with a slider on a scale from 0 to 100. To assess perceptions of competence, we asked: “How competent do you think advisor 1 is regarding such investment recommendations?” Participants answered on a 7-point Likert scale (from (1)“not competent at all” to (7)“extremely competent”).
4.9.1.3 Design
We manipulated convergence within participants, and conflict of interest between participants. In the conflict of interest condition, experts were introduced this way: “The three advisors have already invested in one of the three options, the same option for all three. As a result, they have an incentive to push that option in their recommendations.” Participants assigned to the independence condition read: “The three advisors are independent of each other, and have no conflict of interest in making investment recommendations.”
4.9.1.4 Materials
We used the same stimuli as in Experiment 4. Identical to Experiment 4, participants saw all four convergence conditions, with two stimuli (i.e. expert predictions) per condition. Each participant therefore saw eight stimuli in total (4 convergence levels x 2 stimuli).
4.9.2 Results and discussion
To account for dependencies of observations due to our within-participant design, we ran mixed models, with a random intercept and a random slope for convergence for participants.
We find evidence for all four hypotheses (see Figure 4.6). To test H1a and H1b, we use the same analyses as in Experiment 4, restricted on the independence condition, and replicate the results. We find a positive effect of convergence on both accuracy (\(\hat{b}_{\text{Accuracy}}\) = 12.337 [10.362, 14.311], p < .001) and competence (\(\hat{b}_{\text{Competence}}\) = 0.562 [0.459, 0.665], p < .001).
The second set of hypotheses targeted the interaction of informational dependency and convergence (Figure 4.6). In the independence condition, the effect of convergence on accuracy was more positive (\(\hat{b}_{\text{interaction, Accuracy}}\) = 3.008 [0.027, 5.988], p = 0.048) than in the conflict of interest condition (\(\hat{b}_{\text{baseline}}\) 9.329 [7.232, 11.426], p < .001). Likewise, the effect of convergence on competence was more positive (\(\hat{b}_{\text{interaction, Competence}}\) = 0.165 [0.014, 0.316], p = 0.032) than in the conflict of interest condition (\(\hat{b}_{\text{baseline}}\) = 0.397 [0.291, 0.503], p < .001).
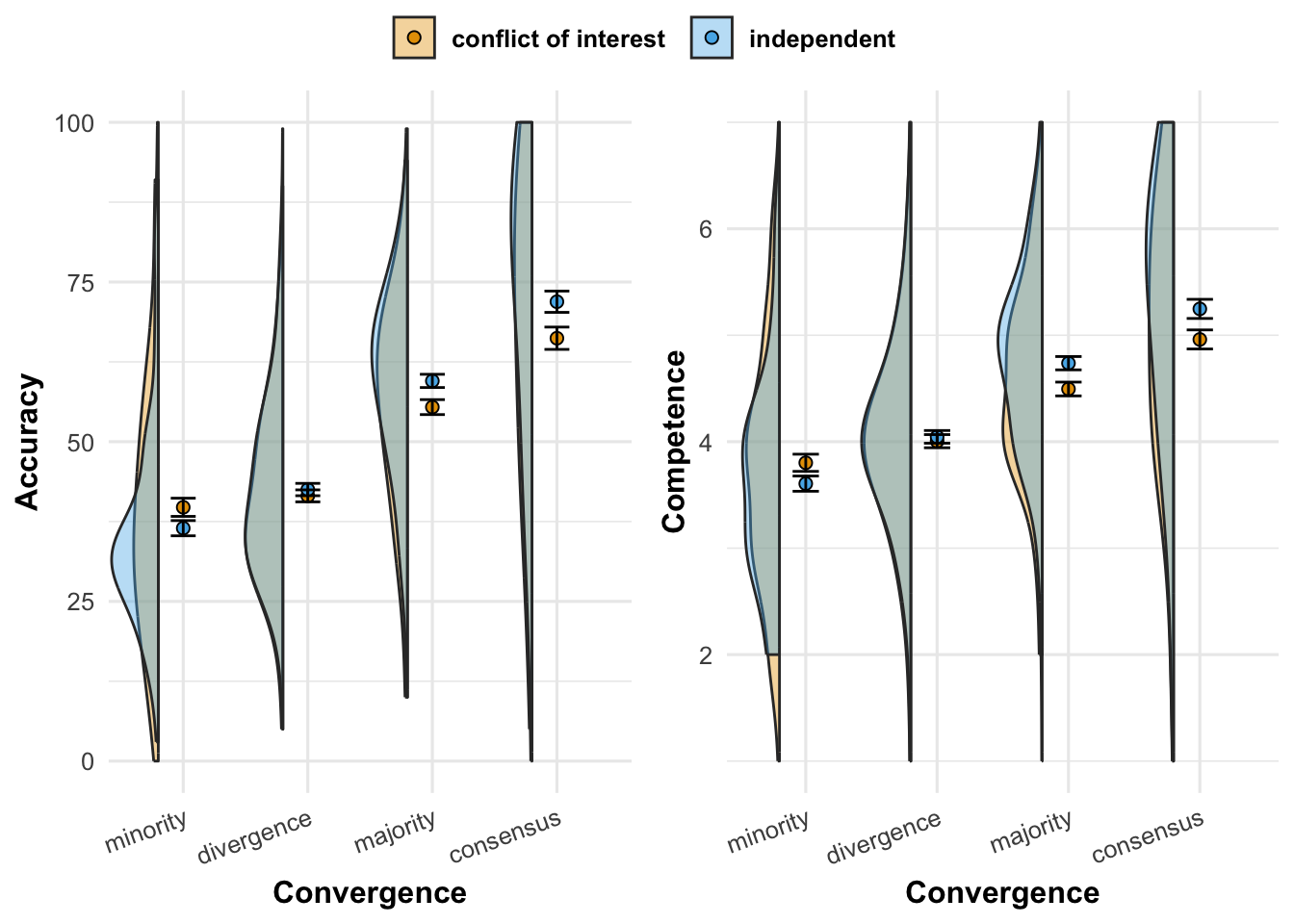
In an exploratory, non-preregistered analysis, we tested whether the effect of convergence is larger on accuracy than on competence. To do so, we first standardized both outcome scores to account for the different scales. We then regressed the outcome score on convergence and its interaction with a binary variable indicating which outcome was asked for (accuracy or competence), while controlling for informational dependency. We find a negative interaction, indicating that convergence had a smaller effect on competence than on accuracy (\(\hat{b}\) = -0.079 [-0.113, -0.044], < .001; units in standard deviations).
4.10 Experiment 6
Experiment 6 is a replication and extension of Experiment 4 in which we test the effect of the number of choice options (three and ten, instead of only three). Our simulations suggested that, at least for some underlying population competence distributions, consensus should be more indicative of competence when there are more choice options, compared to fewer (see ESM).
First, considering only the three options condition, we ran a direct replication of experiment 4. Second, following the results from our model, we predict that
H1: The effect of convergence on accuracy (H1a) is more positive in a context when informants can choose among ten response options compared to when they can choose among only three.
H2: The effect of convergence on competence (H1b) is more positive in a context when informants can choose among ten response options compared to when they can choose among only three.
4.10.1 Methods
4.10.1.1 Participants
We ran a power simulation to inform our choice of sample size. All assumptions and details on the procedure can be found on the OSF. We used previous experiments and estimates of our models to inform our choice of parameter values. We ran two different power analyses, one for each outcome variable. We set the power threshold for our experiment to 90%. The power simulation for accuracy suggested that for 140 participants we would cross the power threshold of 90% for the interaction effect (power = 0.928). The simulation for competence suggested that with 300 participants, we would detect an interaction with a power of 87%. Due to budget constraints, we considered aiming for a sample of 300 participants as good enough, although slightly below our threshold. Due to two failed attention checks, our final sample consisted of 298 subjects, recruited, as in all experiments, in the UK and via Prolific (149 female, 149; \(age_\text{mean}\): 42.091, \(age_\text{sd}\): 13.065, \(age_\text{median}\): 40).
4.10.1.2 Procedure
We used the same procedure as in Experiment 4, with the addition of one condition described below.
4.10.1.3 Design
The number of choice options was manipulated between participants. Participants were randomly assigned to either see stimuli with three options (as in Experiment 4), or stimuli with ten options. Participants assigned to the ten options condition were divided into one of two distinct sub-conditions: one in which the range of the answers corresponds to the range of the three options condition, and another with increased range (see ESM). We found no differences between the two sub-conditions and collapsed them into a single ten options condition.
4.10.1.4 Materials
For the three options condition, we used the same stimuli as in Experiments 4 and 5. For the ten options condition, we created new sets of stimuli (see ESM). Identical to Experiments 4 and 5, participants saw all four convergence conditions, with two stimuli per condition. Each participant therefore saw eight stimuli in total.
4.10.2 Results and discussion
To account for dependencies of observations due to our within-participant design, we ran mixed models, with a random intercept and a random slope for convergence for participants.
We replicate the results of experiment 4, but do not find evidence for an interaction between convergence and the number of choice options. To match the setting of experiment one, we reduced the sample to half of the participants, namely those who were assigned to the three options condition. On this reduced sample, we ran the exact same analyses as in experiment 4 and replicated the results. We find a positive effect of convergence on both accuracy (\(\hat{b}_{\text{Accuracy}}\) = 15.679 [14.112, 17.246], p < .001) and competence (\(\hat{b}_{\text{Competence}}\) = 0.65 [0.564, 0.736], p < .001). This finding also holds across the entire sample, pooling three and ten choice option observations (\(\hat{b}_{\text{Accuracy}}\) = 16.305 [15.124, 17.485], < .001; \(\hat{b}_{\text{Competence}}\) = 0.675 [0.611, 0.739], < .001).
We do not find evidence of an interaction, i.e. evidence that the number of choice options changes the effect of convergence (\(\hat{b}_{\text{interaction, Accuracy}}\) = 1.252 [-1.11, 3.613], = 0.298; \(\hat{b}_{\text{interaction, Competence}}\) = 0.05 [-0.078, 0.178], = 0.442).
We tested whether the effect of convergence is larger on accuracy than on competence in an exploratory, non-preregistered analysis. To this end, we first standardized both outcome scores to account for the different scales. We then regressed the outcome score on convergence and its interaction with a binary variable indicating which outcome was asked for (accuracy or competence), while controlling for the number of choice options. In line with all previous experiments, we find a negative interaction, indicating that convergence had a smaller effect on competence than on accuracy (\(\hat{b}\) = -0.049 [-0.075, -0.023], < .001).
Experiment 6 replicates Experiments 3 and 4 (independence condition), but suggests that the number of options the informants choose from does not powerfully affect participants’ estimates of the informants’ accuracy or competence. In the ESM, we show that, compared to our model, participants underestimate the effect of the number of choice options.
4.11 General discussion
Using both analytical arguments and simulations, we have shown that, under a wide range of parameters, more convergent answers tend to be more accurate, and to have been made by more competent informants.
In two experiments (Experiment 1, and independence condition of Experiment 3), we find that participants presented with a set of more (rather than less) convergent numerical estimates find the estimates more accurate, and the individuals making the estimates more competent, thus drawing normatively justified inferences. Experiment 2 suggests that participants do not think that a discussion between the individuals makes their convergence less indicative of accuracy or their competence. By contrast, Experiment 3 reveals that, when the individuals making the estimates are systematically biased by a conflict of interest, participants put less weight on the convergence of their estimates.
Similar results are obtained in a categorical choice context, in which participants see the answers of individuals made within a limited set of options. Experiments 4, 5 (independence condition), and 6 show that, the more the answers converge, the more participants believe them to be accurate and the individuals who made to be competent, again drawing normatively justified inferences. Experiment 5 shows that these inferences are weakened when the convergence can be explained by a conflict of interest (as in Experiment 3). Experiment 6 fails to find an effect of the number of options.
We also observe that, in line with our simulations, participants draw stronger inferences from convergence to accuracy than to competence in five of the six experiments.
On the whole, participants thus appear to draw normatively justified inferences: 1. They infer that more convergent answers are more accurate; 2. They infer that more convergent answers are coming from more competent informants; 3. The inference on accuracy tends to be stronger than the inference on competence ; 4. Both the inference on accuracy and on the inference on competence are weaker when the informants have a conflict of interest, but not when they are merely discussing with each other. The only exception appears to be that participants do not take into account the number of options in categorical choices scenarios.
4.12 Conclusion
When people see that others agree with each other, they tend to believe that they are right. This inference has been evidenced in several experiments, both for numerical estimates (e.g. Molleman et al. 2020; Yaniv, Choshen-Hillel, and Milyavsky 2009; Budescu and Rantilla 2000; Budescu et al. 2003; Budescu and Yu 2007), and for categorical choices (e.g., Morgan et al. 2012; for review, see Mercier and Morin 2019). However, these experiments do not test whether this inference of accuracy of the information extends to an inference of competence of the informants. Moreover, by their design, participants arguably assumed a degree of competence among the informants. For instance, when children are confronted with several individuals who agree on how to name a novel object (e.g. Corriveau, Fusaro, and Harris 2009), they can assume that these (adult) individuals tend to know what the names of objects are. If a certain competence of the informants is assumed, then well-known results from the literature on judgment aggregation–the wisdom of crowds–show that the average opinion of a set of individuals is, in a wide range of circumstances, more likely to be accurate than that of a single individual (e.g. Larrick and Soll 2006).
Here, we assumed no prior knowledge of individual competence, asking the question: if we see informants, whose competence is unknown, converge on an answer, is it rational to infer that this answer is more likely to be correct, and that the informants are likely to be competent? We have shown that the answer is yes on both counts–assuming there is no systematic bias among the informants. An analytical argument and a series of simulations revealed that, for both the numerical choice context and the categorical choice context, the more individuals agree on an answer, the more likely the answer is correct, and the more likely the individuals are competent, with the former effect being stronger than the latter. Moreover, this is true for a wide range of assumed population distributions of competence. In a series of experiments, we have shown that participants (UK) draw these inferences, but that they do so less when there is reason to assume a bias among informants.
The results–both simulations and experiments–are a novel contribution to the wisdom of crowds literature. In this literature–in particular that relying on the Condorcet Jury Theorem–a degree of competence is assumed in the individuals providing some answers. From that competence, it can be inferred that the individuals will tend to agree, and that their answers will tend to be accurate. Here, we have shown that the reverse inference–from agreement to competence–is also warranted, and that it is warranted under a wide range of circumstances: If one does not suspect any systematic bias, convergence alone can be a valid cue when determining who tends to be an expert. This finding qualifies work suggesting that people need a certain degree of expertise themselves, in order to figure out who is an expert (Nguyen 2020; Hahn, Merdes, and Sydow 2018).
The present experiments show that people draw inferences from convergence to accuracy and to competence, but then do not precisely show how they do it. As suggested in the introduction, it is plausible that participants use the combination of two heuristics: one leading them from convergence to accuracy, and one from accuracy to competence. This two step process is coherent with the observation that the inference from convergence to accuracy (one step) is stronger than that from convergence to competence (two steps). However, our results are also compatible with participants performing two inferences from convergence, one to accuracy and one to competence, the latter being weaker because the inferences roughly follow the normative model. Our results are coherent with work on other mechanisms of epistemic vigilance that process the combination of several informants’ opinions, showing that these mechanisms rely on sensible cues, but also systematically fail to take some subtle cues into account (Mercier and Morin 2019).
A most prominent context in which the inferences uncovered here might play a role is that of science. Much of science is counterintuitive, and most people do not have the background knowledge to evaluate most scientific evidence. However, science is, arguably, the institution in which individuals end up converging the most in their opinions (on consensus being the defining trait of science by contrast with other intellectual enterprises, see Collins 2002). For instance, scientists within many disciplines agree on things ranging from the distance between the solar system and the center of the galaxy to the atomic structure of DNA. This represents an incredible degree of convergence. When people hear that scientists have measured the distance between the solar system and the center of the galaxy, if they assume that there is a broad agreement within the relevant experts, this should lead them to infer that this measure is accurate, and that the scientists who made it are competent. Experiments have already shown that increasing the degree of perceived consensus among scientists tends to increase acceptance of the consensual belief (Van Stekelenburg et al. 2022), but it hasn’t been shown yet that the degree of consensus also affects the perceived competence of scientists.
In the case of science, the relationship between convergence and accuracy is broadly justified. However, at some points of history, there has been broad agreement on misbeliefs, such as when Christian theologians had calculated that the Earth was approximately six thousand years old. To the extent that people were aware of this broad agreement, and believed the theologians to have reached it independently of each other, this might have not only fostered acceptance of this estimate of the age of the Earth, but also a perception of the theologians as competent.
The current study has a number of limitations. In our simulations, we assume agents to be independent and unbiased. Following previous work generalizing the Condorcet Jury Theorem to cases of informational dependency (Ladha 1992), more robust simulations would show that–while still assuming no systematic bias–our results hold even when agents influence each others’ answers. Regarding our experiments, if the very abstract materials allow us to remove most of the priors that participants might have, they might also reduce the ecological validity of the results. Although the main results replicate well across our experiments, and we can thus be reasonably certain of their robustness, it’s not clear how much they can be generalized. Experimental results with convenience samples can usually be generalized at least to the broader population the samples were drawn from–here, UK citizens (Coppock 2019). However, we do not know whether they would generalize to other cultures.
These limitations could be overcome by replicating the present results in different cultures, using more ecologically valid stimuli. For instance, it would be interesting to test whether the inference described here, from convergence to competence, might be partly responsible for the fact that people tend to believe scientists to be competent (Cologna et al. 2024). Finally, future studies could also attempt to systematically model cases of informational dependencies more subtle than those used in Experiments 3 and 5, to derive and test normative predictions.
4.12.0.1 Data availability
Data for all experiments and the simulations is available on the OSF project page (https://osf.io/6abqy/).
4.12.0.2 Code availability
The code used to create all results (including tables and figures) of this manuscript is also available on the OSF project page (https://osf.io/6abqy/).
4.12.0.3 Competing interest
The authors declare having no competing interests.